在Studio中我们可以看到不同类型的Dataset对象,如下图:
![]()
图表 13
在dorado开发中,dataset作为最核心的对象,承担着整个系统承上启下的作用。而当我们将一个企业应用系统中导入dorado时,其主要考虑点也就是dataset。因此在dorado中也就提供了各种类型的dataset对象,为了更方便的与各种应用场景整合。
如:
AutoSqlDataset以及SqlDataset用于方便JSP+Struts+JDBC架构类型的应用环境;
MarmotDataset与CustomDataset是为了方便与系统中基于POJO开发的应用系统;
FormDataset是为了与Request做更好的结合,其作用类似于Struts中的FormBean;
不同类型Dataset的区分,主要在于其读取数据和保存数据环节上有所不同(详细说明参看后文)。而在读取数据之后在dorado中表现层开发中则没有区别。
下面我们再看一张图,一下是各种类型dataset的继承关系图:

注意其中所有的dataset都实现了com.bstek.dorado.data.Dataset接口。常用的dataset有:
- AutoSqlDataset
- SqlDataset
- FormDataset
- CustomDataset
- DODataset
- MarmotDataset
com.bstek.dorado.data.Dataset中规定必须实现的主要方法有:
记录移动和增删改的记录管理方面的方法:
方法 |
说明 |
insertRecord |
新增记录 |
deleteRecord |
删除记录 |
setValue,getValue |
修改当前记录或访问当前记录的值 |
moveProv,moveNext,moveLast,moveFirst |
记录移动方法 |
数据集本身的管理方法
方法 |
说明 |
clear |
清空Dataset中所有的数据 |
load |
根据dataset已设定的条件读取外部数据 |
fromDO,fromSingleDO,toDO,toSingleDO |
与POJO对象的交互函数 |
update |
把用户对Dataset中数据的操作更新到外部数据中 |
isFirst,isLast |
当前记录指针位置判断函数 |
getCurrent |
获取当前记录指针对应的record对象 |
getPageSize,setPageSize |
设定分批数据下载时,单批记录的总记录数,在分批数据下载提高系统运行效率时使用 |
getPageIndex,setPageIndex |
设定分批数据下载时指定下载查询结果总批次中的指定具体某一个批次数据的信息,在分批数据下载提高系统运行效率时使用 |
getPageCount,setPageCount |
设定查询结果总分页数信息,在分批数据下载提高系统运行效率时使用 |
集合对象管理方法:
方法 |
说明 |
addDatasetListener,removeDatasetListener |
添加和移除dataset的listener对象 |
addField,addDummyField,addLookupField |
添加各种类型的字段 |
properties |
与Dataset相关的一组属性值,类似与元数据,具体功能可由开发人员扩展 |
parameters |
Dataset的参数集合,参数集合默认被应用于动态查询中相关参数的管理 |
fieldSet |
Dataset的Field集合对象 |
recordSet |
Dataset的Record集合对象 |
以上基本方法在com.bstek.dorado.data.AbstractDataset中已经提供了默认的实现。Dorado中的所有类型的Dataset都从该类继承下来。由于AbstractDataset实现了fromDO,fromSingleDO,toDO,toSingleDO等与POJO对象的交互方法,从而使得所有类型的Dataset对象都具有与POJO对象的直接转换功能。
Dataset中POJO转换使用说明
Dorado中的各种Dataset都提供了一些方法,用于初始化dataset的数据,例如:
dataset.insertRecord(); |
以上代码就是利用dataset的insertRecord()方法插入一条空纪录,并利用set方法设置dataset中相关字段的值,set方法可以支持多种类型的数据,例如int,string,float,double,date等等。
但是这种使用方式比较的费劲。
因此dorado中的dataset提供了与POJO对象的转换功能,使用时我们只需要将dataset与需要转换的POJO对象设着好映射关系。再通过dataset与POJO的转换方法实现POJO数据转换为dataset的数据,同样也能实现dataset中的数据转换为POJO的数据。
如存在一个POJO对象Dept.java,基本的设定如下:
Dept.java |
package hr.manage.domain; |
则我们就可以设定一个dataset的objectClazz为"hr.manage.domain.Dept"。
并在dataset中新增三个字段,分别为:
deptId,属性设置如下:
属性 |
值 |
dataType |
string |
label |
部门编号 |
name |
deptId |
property |
deptId |
branchId,属性设置如下:
属性 |
值 |
dataType |
string |
label |
分公司编号 |
name |
branchId |
property |
branchId |
deptName,属性设置如下:
属性 |
值 |
dataType |
string |
label |
部门名称 |
name |
deptName |
property |
deptName |
其中的property属性与dataset的objectClazz属性对应的POJO对象的属性相对应,例如deptId字段的定义就表示它与Dept.java中的deptId属性相对应。
另外Field与POJO的属性映射还存在一种默认的约定,如以上三个字段的设定中name与Dept中的属性名称完全相同,则我们可以在Field的设置中省略property属性的设定。只有在Field的名称与POJO不一致时,我们才有必要设定Field的property属性,去处property属性设置后,datasetDept的设计视图就如下:
<Dataset id="datasetDept" type="Wrapper" wrappedType="Marmot" objectClazz="hr.manage.domain.Dept" dataProvider="deptService" method="getDepts" pageSize="10"> |
另外Field与POJO中的属性对应设定中还支持嵌套映射。如下面的User类中包含Employee对象:
public class User implements java.io.Serializable { |
如果一个与User对应的Dataset还想获取employee中的信息,我们就可以使用如下的方式设定:
<Dataset id="datasetEmployee" type="Wrapper" wrappedType="Marmot" objectClazz="hr.manage.domain.Employee" dataProvider="employeeService" method="getEmployees" pageSize="10"> |
在以上的代码中设定birthday 字段的property属性为"employee.birthday"。这样datasetEmployee与User对象进行数据转换的过程中,就可以存取employee中的birthday信息。
调用dataset的对象转换方法fromDO(),toDO()等,转换方法会根据映射关系设定,自动实现数据转换处理。
目前支持与Dataset数据转换的POJO对象有:
单个的Bean、java.util.Map的派生类、java.util.Collection的派生类 或对象数组.此方法会自行根据data的类型决定处理方式.对于Map或其派生类,Collection和它的派生类,以及对象数组来说,要求其中的包含的Java对象统一的都为dataset中objectClazz指定的类型。
使用范例可以参考<<dorado 5 快速入门(二) v1.1.doc>>中使用CustomDataset实现部门数据的维护部分。
分类简述DBDataset
在dorado for JDBC方式的开发中,通常我们都直接利用DBDataset实现,我们可以利用DBDataset集成的查询以及数据保存功能协助我们快速的实现业务逻辑简单的系统开发,也可以在DBDataset基本功能的基础上利用dorado提供的实现类或监听器机制添加复杂的业务逻辑代码完成系统功能开发。
目前DBDataset包含两个Dataset子类:SqlDataset和AutoSqlDataset。其区别和使用将在后文描述。
在DBDataset中实现了doLoad(),doUpdate方法,用来与数据库做交互,实现查询、分页和批量数据保存等功能。
使用DBDataset时,重点关注的几个属性为:
dataSource:DBDataset更新和查询时操作的目标数据库(DataSource.xml中配置),如果不指定,系统默认使用Setting.xml配置文件中的defaultDataSource配置的数据源;
originTable:DBDataset对数据库做增删改操作时的目标数据库中的目标数据表,originTable只能指定一个目标数据表,因此DBDataset本身集成的数据更新功能也是只能针对单个表进行,多个表需要通过实现类或Listener添加逻辑代码实现;
keyFields:originTable所对应数据库目标表的主键字段。对一个数据库中的数据表进行更新时,所使用的SQL语句中通常都包含where关键字,用以定位相关记录做删除和更新动作,如:
update employee set employee_id='BAIXIAOBO' where employee_id='ANLIN'; |
DBDataset中由于同时存在增删改状态的各种记录,如果同时提交,则在DBDataset中我们就必须指定keyFields属性,以便DBDataset生成更新SQL语句时拼写正确的where语句。
coungSql:dorado的DBDataset支持分页技术,并且是采用数据库分页技术而不是在内存中实现分页。这种分页机制大大优于获取ResoultSet后再分页的处理方式,但是使用这种处理方式,我们就无法通过ResultSet获取总的记录数信息,从而使得dataset无法计算出总页数,在DBDataset中默认是通过countSql方式获取记录总数。这个属性并不需要开发人员指定,而是在DBDataset运行期间,通过DBDataset本身的查询语句自动生成。
load(ResultSet rs):用以导入一个ResultSet对象。DBDataset可以很方便的利用一个ResultSet对象填充。在应用系统开发时,该方法较多的被应用于存储过程调用。对于一些存在较多存储过程的业务系统可以通过这种方式将数据导入到DBDataset中。
详细内容参考:DBDataset详细说明。
分类简述SqlDataset
SqlDataset属于DBDataset的一个子类。在DBDataset的基础上新增了sql属性,允许开发人员自行定义其sql属性。Sql语句要求是DQL(数据库查询语句)而非DDL,DML,DCL等其它管理维护类的SQL语句。SqlDataset则通过该属性执行数据库查询。该处sql语句的使用的语法完全与我们所使用的数据库相关,由数据库支持的SQL语法规则决定。
SqlDataset中sql属性还支持参数设定,我们可以通过动态的修改参数值从而得倒不同的查询结果集合。如我们希望通过指定不同的部门查询不同的员工,sql语属性就可以这么定义:
select * from employee where dept_id = :deptId |
其中":deptId"就是一个变量名,在SqlDataset中变量名的命名规则为:冒号加变量名。如上sql语句中的deptId参数。如果我们在运行期间使用如下代码对dataset的参数赋值,并调用flushData方法:
dataset.parameters().setValue("dept_id","D11"); |
则SqlDataset会自动的将D11作为sql属性中的值并进行查询。
在SqlDataset的内部处理机制中,是通过PreparedStatement使用select * from employee where dept_id=?进行编译,并在SqlDataset获得参数值之后设定PreparedStatement中的第一个参数的值,通过PreparedStatement实现查询。
详细内容参考:SqlDataset详细说明。
分类简述AutoSqlDataset
AutoSqlDataset也是DBDataset的一个子类,与SqlDataset不同,AutoSqlDataset的查询是通过一个可视化设计器完成的(而不是SqlDataset中的sql属性定义)。如下图:
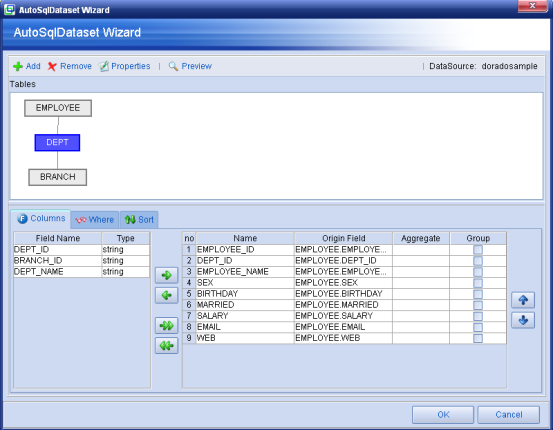
图表 14
借助于向导模式我们可以快速的设计一个查询sql。在AutoSqlDataset中,查询条件的匹配都是通过一些XML方式加以描述。如下面的sql语句:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex='1' and salary<5000 ORDER BY EMPLOYEE.EMPLOYEE_ID DESC |
在AutoSqlDataset中,利用向导生成的xml配置文件,将会将以上的SQL语句拆分为
一个JOIN对象:
<Join name="DEPT" originTable="DEPT" keyFields="DEPT_ID" sourceTable="EMPLOYEE" sourceKeyFields="DEPT_ID" /> |
四个AutoSqlField:
<Field name="EMPLOYEE_ID" originField="EMPLOYEE_ID" table="EMPLOYEE" /> |
两个BaseMatchRule对象:
<MatchRule level="1" value="true" table="EMPLOYEE" originField="SEX" operator="=" /> |
一个sortRule对象:
<SortRule originField="EMPLOYEE_ID" table="EMPLOYEE" descent="true" /> |
以上的配置如果通过Studio提供的AutoSqlDataset设计向导实现设计,在开发效率上会比SqlDataset大有提高。另外我们也应该注意到AutoSqlDataset中的所有查询条件设定都是与数据库本身无关的,利用dorado中提供的方言机制,可以很轻松的从一种数据库切换为另一种数据库,比较而言会比SqlDataset的移植性高很多。这也是AutoSqlDataset的一大优势。
同样,AutoSqlDataset也支持参数使用方式,例如如上的sql语句采用参数定义之后sql语句可以调整为:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=:sex and salary<:salary |
而采用AutoSqlDataset的定义方法,我们修改其中的BaseMatchRule的定义,修改后代码如下:
<MatchRule level="1" value=":sex" table="EMPLOYEE" originField="SEX" operator="=" /> |
同样如果用AutoSqlDataset实现一个查询,我们就可以在Client端添加如下的代码:
dataset.parameters().setValue("sex", true); |
则AutoSqlDataset会自动的将"true"与"5000"作为BaseMatchRule中的参数值并进行查询。
在AutoSqlDataset的内部处理机制与SqlDataset类似,也是通过PreparedStatement使用如下的sql语句实现编译:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=? and salary<? |
并在AutoSqlDataset获得参数值之后设定PreparedStatement中的不同参数的值,通过PreparedStatement实现查询。
详细内容参考:AutoSqlDataset详细说明。
分类简述CustomDataset
CustomDataset是最基本的Dataset。与DBDataset不同,该类型的Dataset无法通过sql属性或MatchRule属性配置自动的去查询和更新数据。使用时可以利用CustomDataset提供的insertRecord和setXXX()方法和getXXX()方法存取dataset中的值,范例如下:
dataset.insertRecord(); |
以上代码就是利用dataset的insertRecord()方法插入一条空纪录,并利用set方法设置dataset中相关字段的值,set方法可以支持多种类型的数据,例如int,string,float,double,date等等。
同样我们也可以利用其父类AbstractDataset对象与POJO对象的数据转换功能直接利用fromDO(),fromSingleDO()等方法实现数据转换。
后面将要介绍的DatasetReference与DODataset,MarmotDataset原理上都与此类似,只是有些功能增强而已。
详细内容参考:CustomDataset详细说明。
分类简述FormDataset
FormDataset提供了与Request对象的集成,可以利用HttpServletRequest对象的parameters属性集合初始化FormDataset。便于我们在dorado页面中可以很方便的通过dataset获取系统请求该页面时产生的request中的信息。
详细内容参考:FormDataset详细说明。
分类简述DODataset
基本功能与CustomDataset类似,并提供了内存分页功能(通过指定supportsPaging="true"实现)。
详细内容参考:DODaaset详细说明。
分类简述MarmotDataset
MarmotDataset主要是针对Marmot框架提供支持,这种类型的Dataset可以很好的支持Spring框架的开发。
详细内容参考:MarmotDataset详细说明。
{kind=link}