基本功能
AutoSqlDataset是一种通过向导定义Dataset内容的一种数据集,应此相比SqlDataset,AutoSqlDataset的定义更为简单和快捷,并且为了增加AutoSqlDataset的应用面,AutoSqlDataset提供了对象方式描述查询语句地定义方式,以及增加了对SQL语句地直接支持。从而使AutoSqlDataset可以实现较为复杂的查询工作。另外AutoSqlDataset还提供了一些优异的特性,使开发人员更为方便的定义与实现查询工作,例如查询分页功能的自动处理机制,查寻条件的逃逸处理机制,查寻条件的复合匹配机制等。这样使得开发人员在实现业务需求时大部分的情况下都可以通过定义而不是自己写SQL语句获取查询结果。当然了作为DBDataset的子类,AutoSqlDataset也提供了数据的持久化能力,很多情况下开发人员可以不写代码而通过Dataset直接将数据保存到数据库中。这个对开发人员来说无疑是非常有意义的。AutoSqlDataset也支持用java编码创建,不过在一般情况下我们建议您使用配置方式创建。这样才能真正的发挥出AutoSqlDataset的快速设计,快速使用,快速保存等综合优势。目前版本的AutoSqlDataset还不能支持union操作。但是其它的基本查询都可以支持。
基本原理说明
AutoSqlDataset实际上是用对象封装和描述SQL语句。例如如下的sql语句:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex='1' and salary<5000 ORDER BY EMPLOYEE.EMPLOYEE_ID DESC |
在AutoSqlDataset中,将以上的SQL语句拆分为几个对象:
对象名称 |
对象定义方式 |
代表的SQL语句 |
JOIN对象DEPT |
<Join name="DEPT" originTable="DEPT" keyFields="DEPT_ID" sourceTable="EMPLOYEE" sourceKeyFields="DEPT_ID" /> |
Left join dept on employee.dept_id=dept.dept_id |
Field对象employee_id |
<Field name="EMPLOYEE_ID" originField="EMPLOYEE_ID" table="EMPLOYEE" /> |
Select employee.employee_id from employee |
Field对象employee_name |
<Field name="EMPLOYEE_NAME" originField="EMPLOYEE_NAME" table="EMPLOYEE" /> |
Select employee.employee_name from employee |
Field对象dept_id |
<Field name="DEPT_ID" originField="DEPT_ID" table="EMPLOYEE" /> |
Select employee.dept_id from employee |
Field对象dept_name |
<Field name="DEPT_NAME" originField="DEPT_NAME" table="DEPT" /> |
Select dept.dept_name from dept |
BaseMatchRule对象1 |
<MatchRule level="1" value="true" table="EMPLOYEE" originField="SEX" operator="=" /> |
Where employee.sex=true |
BaseMatchRule对象2 |
<MatchRule level="1" value="5000" table="EMPLOYEE" originField="SALARY" operator="<" /> |
Where employee.salary<5000 |
sortRule对象 |
<SortRule originField="EMPLOYEE_ID" table="EMPLOYEE" descent="true" /> |
order by employee.employee_id desc |
以上的各个对象的定义在开发的时候并不需要手工输入,可以通过配置快速完成,如下图:

图表 37
这种采用对象描述SQL的方式,使得我们在dorado的Studio中可以快速的设计和生成sql语句。在开发效率上会比SqlDataset大有提高。
参数处理机制
AutoSqlDataset也支持参数使用方式,参数命名方式:冒号+变量名.
例如上节的sql语句采用参数定义之后:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=:sex and salary<:salary |
系统执行时使用预存储过程编译该SQL:
PreparedSatatement pst = conn.prepareStatement("select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=? and salary<?"); |
这种参数处理方式在AutoSqlDataset中可以用如下方法设定MatchRule对象:
<MatchRule level="1" value=":sex" table="EMPLOYEE" originField="SEX" operator="=" /> |
系统执行时我们可以通过如下的方式给AutoSqlDataset中的参数赋值:
dataset.parameters().setValue("sex", true); |
AutoProcessParameters
AutoSqlDataset还提供了一种特殊的功能,查看下图:
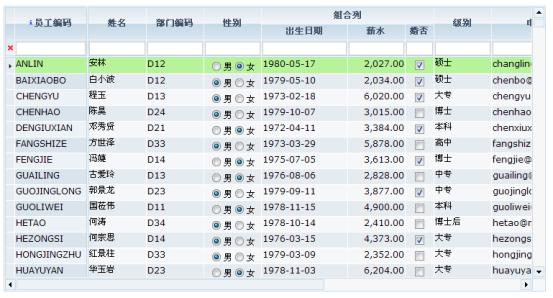
图表 38
与AutoSqlDataset绑定的数据表格,如果我们将他的filterBar打开,就是上图中我们看到的表头下方的数据输入行,该行称为数据表格的filterBar.用户可以在该处输入各种查询条件对dataset执行查询动作。对于AutoSqlDataset,我们需要打开autoProcessParameters属性,设置该属性为true就可以支持filterBar的查询功能。对于那些希望自定义查询的AutoSqlDataset对象,可以设置该属性为false.该属性默认值为false.
Distinct
用于AutoSqlDataset执行查询时所用的SQL查询语句中自动产生distinct关键字。
selectAllField
用于设定AutoSqlDataset执行查询时是否取出所有字段的信息,否则就按照自身Fields的配置取出相关字段。
MatchRule
AutoSqlDataset中特别值得一提的是MatchRule的使用,MatchRule主要用于定义SQL语句中的where字句。
MatchRule的基本格式如下:
<MatchRule |
其中的属性说明如下:
属性 |
说明 |
originField |
匹配规则的原始字段,生成where条件时根据该属性生成字段的字符串,与table属性配合使用,如xml定义如下: |
<MatchRule |
最终生成的sql为:
Where dept.branch_id='D1' |
蓝色字体就是originField的作用|
Table |
原始字段(originField)所属的表名,生成where条件时根据该属性生成字段的字符串,与originField属性配合使用,如xml定义如下: |
<MatchRule |
最终生成的sql为:
Where dept.branch_id='D1' |
蓝色字体就是table的作用|
Operator |
设定比较操作符,生成where条件时根据该属性生成字段的字符串,与originField,value属性配合使用,如xml定义如下: |
<MatchRule |
最终生成的sql为:
Where dept.branch_id='D1' |
蓝色字体就是operator的作用。|
dataType |
匹配值的数据类型 |
Value |
匹配值 |
<MatchRule |
最终生成的sql为:
Where dept.branch_id='D1' |
蓝色字体就是operator的作用。|
escapeEnabled |
是否要启用本匹配规则上的可逃逸功能,与escapeValue属性配合使用 |
escapeValue |
逃逸值, 逃逸值是一个具体的数值,当逃逸值与匹配值相等时本匹配规则将被完全忽略. |
Enabled |
设置整个匹配规则是否有效,如果设置为false时,dataset执行查询时将忽略该MatchRule对象 |
Level |
设置该规则对象的级数. |
useSqlParameter |
设置是否在生成SQL时使用数据库预编译参数.默认为true, 在某些数据库中(例如Oracle),对于CHAR类型的字段如果在使用预编译参数时,我们必须传入已补齐尾部空格的匹配值, 否则将无法得到正确的查询结果. 为了避免这一问题的出现我们可以将对应此字段的匹配条件设为不使用数据库预编译参数. |
MatchRule简单的使用我们通过前面的例子已经可以明白。
下面我们再看看几个特殊特性:
escapeEnabled与escapeValue
下面我们就前面的一个查询例子加以说明,观察如下的sql语句:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=:sex and salary<:salary ORDER BY EMPLOYEE.EMPLOYEE_ID DESC |
对于这个SQL语句,如果我们未指定其中的sex,salary参数的值,系统查询时就会使用
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where employee.sex=false and salary<0 ORDER BY EMPLOYEE.EMPLOYEE_ID DESC |
则结果就为空。
为了避免这种情况,我们通常对会在系统中通过判断的方式定义SQL语句:
String sex = (String)request.getParameter("sex") |
而在查询系统中的要求往往是如果用户没有输入sex,就按照如下的sql语句实现查询:
select employee.employee_id, employee.employee_name, employee.dept_id, dept.dept_name from employee left join dept on employee.dept_id=dept.dept_id where salary<:salary ORDER BY EMPLOYEE.EMPLOYEE_ID DESC |
注意这儿的employee.sex=:sex语句已经不见了,这种特性我们称之为逃逸功能。在很多系统的开发中我们都需要通过程序员的if判断来动态生成sql语句。如:
if (sex!=null && "".equals(sex)==false){ |
这样就造成很多垃圾和无用的代码。这一方面在现在很多新的框架中已经陆续有比较好的逃逸解决方案。比较老的系统本人接触的有IBatis中的ISNOTEMPTY配置,就是很不错的一种处理方式。
MatchRule中的escapeEnabled就与此类似。
而escapeValue属性就对应为以上if程序代码中的条件
sex!=null && "".equals(sex)==false |
该条件时说如果字符串为空就逃逸。
MatchRule通过escapeValue指定逃逸条件,默认条件为空,也就是说当dataset执行查询时发现查询参数为空时,就忽略该MatchRule对象。当然了我们也可以通过escapeValue自定义逃逸的条件,例如当sex参数的值为all时,我们希望系统查询所有的用户,则可以使用如下的代码定义:
<MatchRule |
level
MatchRule中的level用来指定设置该规则对象的级数.
该级数的默认值为1.级数的设定与WHERE片断中的括号生成相关. 当某几个规则对象的级数高于周围的其它规则对象时,AutoSqlDataset会在生成WHERE片断时自动在这几个规则对象的两端生成一对括号
看例子说明,如查询sql,查询部门编号为D11和D12的所有男员工:
select employee.* from employee where employee.sex=true and (employee.dept_id='D11' |
employee.dept_id='D12') |
|---|
AutoSqlDataset中的matchRule的定义如下:
<MatchRule level="1" value="true" table="EMPLOYEE" originField="SEX" operator="=" /> |
其中sex所属MatchRule的level为1,其它MatchRule的level都为2.从上面的范例可以看出AutoSqlDataset会自动地根据Level设定为SQL中的WHERE语句片断加上匹配的括号对。
MatchRule的分类
MatchRule一共有三种:
BaseMatchRule:匹配单个字段,我们前面所举的例子基本都是BaseMatchRule;
AndOrMatchRule: 用于描述AutoSqlDataset的WHERE片断中的and/or逻辑连接符的规则对象,多个BaseMatchRule之间如果不定义AndOrMatchRule,则默认生成WHERE语句时自动使用and的匹配关系;
SqlMatchRule: 用于描述AutoSqlDataset的WHERE片断的SQL匹配规则对象.可以在该对象的sql属性中直接设定查询WHERE语句中的SQL片断,好处是不受BaseMatchRule的限制,可以加入数据库本身提供的特殊函数以及计算公式,如:
<MatchRule level="1" value="true" escapeEnabled="false" table="EMPLOYEE" originField="SEX" operator="=" /> |
最终生成的where语句为:
where emplolyee.sex=true and (employee.dept_id='D11' |
employee.dept_id='D12') and employee.birthday<to_date(:startDate , 'yyyy-MM-dd') |
|---|
AutoSqlDataset向导说明
以上我们通过基本功能的说明大致了解了AutoSqlDataset的工作原理,粗看显得使用起来较为复杂,实际上根本不用当心。Dorado的Studio中提供了AutoSqlDataset的向导配置界面,利用图形化和向导的方式配置以上接触到的各种对象。这样开发人员在实际使用AutoSqlDataset开发时,基本上不需要编写SQL语句,当然了,开发人员对于SQL编程还是需要有一定了解的。了解基础的SQL编程对使用AutoSqlDataset还是很重要的。配置AutoSqlDataset的过程是通过向导一步一步的设置的过程,在Module或ViewModel中通过点击Outline左侧的AutoSqlDataset按钮可以打开配置AutoSqlDataset的向导。
图表 39
这个向导同上一节SqlDataset生成SQL的向导过程相同,不同的是SqlDataset通过向导生成的是一条SQL,而这里是直接生成AutoSqlDataset配置。
添加AutoSqlDataset必须先配置好dataSource(参考dorado中的数据连接配置说明),配置好datasource之后,我们需要先启动Dorado的Service,然后才可以利用向导作数据库连接配置(dorado从web应用中获取数据连接),点击AutoSqlDataset按钮打开向导。

图表 40
图表 41 AutoSqlDataset向导 选择DataSource和数据库表
向导的第一步是选择一个合适的DataSource,并从该DataSource中指定一个主表对应到当前的AutoSqlDataset。图中"DataSource"是项目中添加的DataSource的列表,选择某一个配置好的datasource之后,如果数据库连接正常,就可以在下边的列表"Tables and Views"中会列出对应DataSource中所有可以添加的数据库表或者视图,基于性能的考虑,目前该列表只会列出查询到的前100张表格我们可以选择一张表格也可以直接在 "Table/View"中填写表名或者视图名,选择的表会作为Dataset的originTable,然后点OK会进入向导主界面。

图表 42 AutoSqlDataset向导 向导主界面
向导主界面元素解释:
按钮"Add":添加从表,点击后出现配置表关联的对话框。
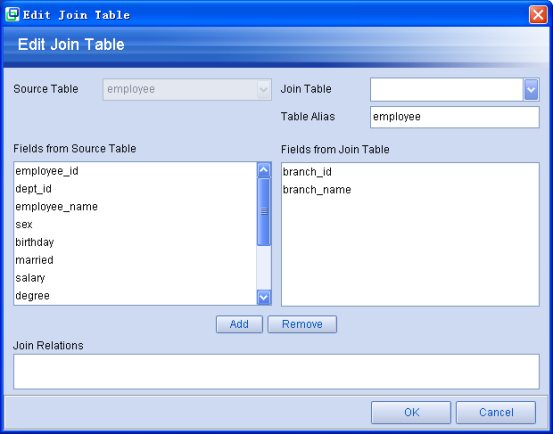
图表 43 AutoSqlDataset向导 配置表关联
对话框中"Source Table"是被关联的表名,在"Join Table"中选择或者填写要要关联的表,在"Table Alias"中可以为要关联的表起一个别名,选好表之后在"Fields from Source Table"和"Fields from Join Table"中分别选择要关联的字段,然后点"Add"按钮添加关联,已经添加的关联可以点击"Remove"按钮删除。
按钮"Remove":删除"Tables"中选中的表,删除之后被删表的相关关联也会被删除。
按钮"Properties":重新选择DataSource和表,点击后会重新打开选择DataSource和数据库表的对话框。
按钮"Preview":预览Dataset中的数据内容,点击后会打开一个数据预览的窗口,这个窗口同Dorado中提供的数据查询工具的窗口相同。

图表 44 AutoSqlDataset 数据预览
标签"DataSource":显示Dataset所使用的DataSource。
多页标签"Columns":"Field Name"和"Type"分别列出"Tables"中选中的Table中的所有字段名和对应的Dorado识别出的类型。一列的四个按钮分别为向Dataset中添加左侧选中的列、删除右侧选中的已经添加的列、添加左侧所有的列和删除右侧已经添加的所有的列。该标签页最右侧的两个向上和向下的按钮可以用来调整添加的列的次序。选中的列的列表的Title中,"no"为字段编号;"Name"为字段名,开发人员可以编辑此项内容改变字段名;"Origin Field"为当前字段对应的数据库表中的字段;"Aggregate"可以选择对当前字段可以计算的统计函数;"Group"为是否对当前字段进行GroupBy,比如选择了Employee表中的sex列和salary列,然后对salary选择了统计函数Sum,对sex设置了Group,那么Dorado最终组装该Dataset时会使用"SELECT employee.sex,SUM(employee.salary) AS salary FROM employee GROUP BY sex"从数据库中查询数据并将查询结果添加到Dataset中。
多页标签"Where":
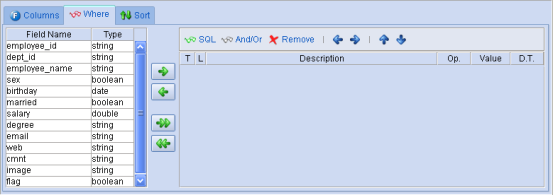
图表 45 AutoSqlDataset向导 配置查询条件
多页标签中一列四个的按钮为向Dataset中添加BaseMatchRule。点按钮"SQL"可以添加SQLMatchRule,点"And/Or"添加AndOrMatchRule,点"Remove"删除选中的添加的MatchRule,点向上或者向下箭头的按钮可以调整MatchRule的先后顺序,点向左或者向右的按钮可以降低或者提高MatchRule的优先级。
MatchRule为查询条件,是一些返回值为布尔型的表达式(SQL中定义的)或者逻辑运算符,MatchRule共三种:BaseMatchRule为基本的表达式,比如:name like "%ZHANG%",sex=:sex等;SQLMatchRule为返回布尔值的的SQL,比如"exists( select * from employed)";AndOrMatchRule为逻辑运算符,有and和or,用来连接前边两类MatchRule。
添加的MatchRule列表中,"T"代表MatchRule的类型,不同MatchRule会有不同的图标;"L"为MatchRule的优先级别,通过点击向左或者向右箭头的按钮来降低或者提高选中的一组查询条件的优先级,优先级高的查询条件会被优先匹配,一般是为通过AndOrMatchRule连接的一组查询条件改变优先级;"Description"、"OP"、"Value"和"D.T."对于不同的MatchRule会有不同,BaseMatchRule时,"Description"为数据库表中字段的名字,"Op"为对这个字段查询条件的操作符,"Value"为查询条件的匹配值,匹配值可以是参数也可以是值,"D.T."为值的类型。SQLMatchRule时,"Description"中填写条件SQL,其他几项不可用。AndOrMatchRule时,"Description"项可以为"And"或者"Or"。
多页标签"Sort":

图表 46 AutoSqlDataset向导 配置排序条件
该标签页中设置Dataset中数据的排序条件,多个排序条件时按照从上到下的顺序依次排序,比如上图中添加的排序条件相当于"order by employee.employee_id asc,employee_id desc"。
通过向导所作的配置最终在AutoSqlDataset都会看到。

图表 47配置好的AutoSqlDataset
此外在完成向导之后还可以进行一些设置。
在向导中设置的表关联最终会添加到Dataset的Joins节点中,对Join通过属性joinMode还可以设置连接的方式,连接方式有"left_outer_join"方式和"select_expression"方式,默认为"left_outer_join"方式。"left_outer_join"方式是通过SQL中的连接方式来选出从表中的数据,"select_expression"是通过SQL的嵌套查询的方式选出从表中的数据,开发人员可以根据实际情况选择合适的连接方式。
在向导中设置的查询条件会被添加到Dataset的MatchRules节点中。

图表 48 配置MatchRule的可逃逸性
在这里对BaseMatchRule还可以设置查询条件的可逃逸性,与可逃逸性相关的属性有escapeEnabled、escapeValue和value,对可逃逸性的解释是这样的:如果设置escapeEnabled为true,那么当value值与escapeValue值相同时,这个MatchRule就会被忽略掉。这个特性的使用一般出现在数据的查询中,比如要求页面打开时要求显示所有数据,只需要把相关查询条件的escapeEnabled设置为true,这时escapeValue为空,那么当页面下载时因为value值没有,那么value就等于escapeValue,这样查询条件就会被忽略,页面就会显示所有数据。
另外,对AutoSqlDataset的Field,还有一些比较重要的属性。
AutoSqlDataset的Field可以通过sql来定义这个字段上的值的来源。
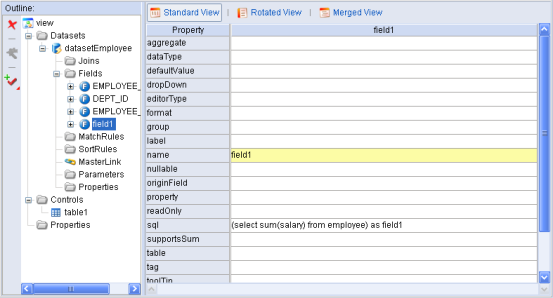
图表 49通过SQL定义AutoSqlDataset的Field
比如我们可以手工添加一个字段field1,在其sql属性可以设置为"(select sum(salary) from employee) as field1",其中括号内的sql必须为返回单条记录的SQL,给合计值起一个别名,别名必须和Field的name属性一致。这样定义的SQL的结果的值会最为Dataset的字段field1的值。
对于某些数据库,比如SQLServer,当数据插入的时候,不能插入约束为自增的字段,这时,需要将字段的updatable属性设置为false,这样,当插入数据时,该字段将会被忽略。
此外我们还可以在服务器端代码中控制AutoSqlDataset的这些属性或者特性,比如下边的代码可以根据客户端穿过来的标志来动态的控制对字段的排序。
String flag = dataset.parameters().getString("flag"); |