Dorado开发中常用的SqlDataset以及AutoSqlDataset都继承自DBDataset,该类位于com.bstek.dorado.data.db包中,主要用以支持数据库的交互工作,其基本功能有:
- 数据查询能力
- 批量增删改的支持(持久化能力)
- 数据分页查询能力
- 动态参数处理机制
- 支持临时字段(DummyField)
- 支持RetrieveAfterUpdate处理机制
对于很多直接使用JDBC与数据库连接,进行系统开发的时候,很多开发人员都会选择DBDataset实现信息系统的开发工作,我们可以利用DBDataset集成度较高的增删该查功能,可以大大地减少系统的开发时间以及降低开发人员的技术储备要求。以及对于系统的后期维护也可以做到快速应变的能力。
下面就一起来看看DBDataset所提供的基本而最有效的功能:
数据查询能力
DBDataset通过SQL语句实现数据库的查询,例如我们使用如下的方式定义SqlDataset:
<Dataset id="datasetEmployee" type="Wrapper" wrappedType="Sql" dataSource="doradosample" originTable="employee"> |
以上是静态设置Dataset的SQL属性的使用方式。这样执行应用程序时,dataset就会取出sql属性中设置的SQL命令。
这种静态的设定方式是在程序设计期间指定的。在实际开发中会有很多的局限性,这样我们就需要借助于Dataset的动态SQL语句编程。在运行期间编写SQL语句。
在程序运行期间,要想动态设置dataset的SQL属性,基本的过程如下:
sqlDataset.setSql("select * from employee"); |
执行dataset的open方法时系统会自动利用sql语句通过JDBC获取ResultSet并将数据导入dataset,同时立即释放JDBC连接资源,保证系统的性能。
数据库查询所需的SQL语句只要保证是查询类型的SQL即可,例如我们也可以用如下的方式实现查询:
String sql = |
DBDataset使用SQL实现查询时所针对的目标数据库,是由它的DataSource属性定义,通常情况下datasource属性都会对应到DataSource.xml文件中的一个数据源。详细说明参考DataSoruce.xml的配置。另外DBDataset也可以不定义datasource属性,系统运行时自动的到系统的Setting.xml文件中查找"common.defaultDataSource"属性配置,根据该配置到DataSource.xml文件中相关的数据源信息。
这里的查询SQL一般情况下只能包含一条完整的SQL语句,不允许被设置成多条SQL语句。
批量增删改能力
从我们对Dataset的了解可以知道,Dataset中包含的数据就相当于一个二维表。在很多使用dorado开发的系统中会大量的存在如下的典型界面:
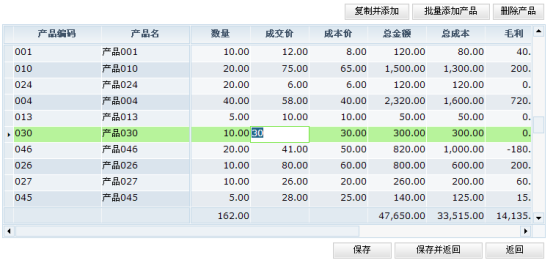
图表 27
在该界面中,我们可以在表格中做数据增删改的多次操作,注意一般情况下用户作这些操作的时候都将修改的信息缓存在Client端,只有当用户最终单击保存按钮的时候才将所有的修改信息(包括增删改的所有信息)提交到服务器,并利用DBDataset实现数据更新处理。DBDataset自动更新时需要注意的几个关键属性为:
- Datasource:定义DBDataset数据查询和数据更新的目标数据库;
- originTable:定义该DBDataset更新数据库的目标表格名称;
- 另外DBDataset还会根据字段的originField属性决定将相关的field中的内容更新到数据库目标表格中的指定字段上;
执行数据更新时有两种动作必须注意,数据修改和数据删除。这两种操作都要求拼写数据库更新SQL的where片段,以便根据where片段定位到数据表中的指定记录作更新或删除的动作。注意此处的更新数据库的SQL语句与查询SQL语句是无关的。在更新SQL中用于定位记录的where片段中涉及到的字段我们称为业务主键:
delete from employee where loginid='admin' |
其中的loginid字段就是一个业务主键。注意此处我们称该字段为业务主键,与数据库主键并不完全一致。业务主键在很多情况下可能会有多个,例如员工与角色的多对多的交叉表中:
CREATE MEMORY TABLE USER_ROLE( |
以上的HSQL表格中,业务主键就是USER_ID和ROLE_ID.
DBDataset通过keyFields属性定义业务主键,如:
<Dataset id="datasetUserrole" type="Sql" originTable="user_role" keyFields="user_id,role_id"> |
DBDataset的持久化能力只负责处理originTable的持久化操作,对于一个多张表join处理出来的查询结果的持久化,系统默认只负责originTable的持久化处理,并将field中table名称与originTable相同的字段的值去实现持久化处理,如果系统同时处理多张表格的持久化一般都利用DBStatement对象实现,或通过DataSourcem.xml配置获取java.sql.Connection对象实现数据保存。
分页查询能力
对于一些大型系统而言,由于其中的海量数据的存在,要求数据库查询有较高的性能。在dorado中可以通过方言解决性能问题,另外dorado的方言还支持分页查询处理。开发人员在使用DBDataset的时候并不需要关注方言的实现方式,而只需要设定dataset的pageSize属性即可,dataset的各种查询命令就会自动利用其所关联的方言处理机制实现查询分页处理。
如下通过PagePilot对象展现dataset的分页信息:
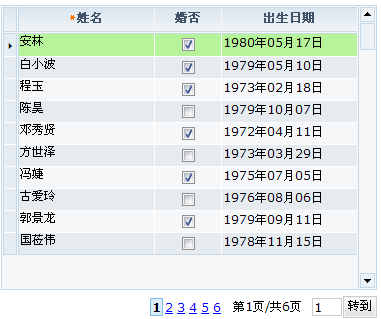
图表 28
该页面上dataset设置的pageSize属性,已经通过一个PagePilot对象绑定到dataset对象上。
<?xml version="1.0" encoding="UTF-8"?> |
动态参数处理机制
前面我们提到DBDataset支持查询处理能力,开发人员可以自定义一个静态的SQL语句,并通过DBDataset的setSql方法设定sql属性,这样DBDataset就可以利用这个sql属性实现查询。这种处理方式只适合编写简单的应用查询。在动态SQL语句中可以包含在程序过程中可以变化的参数,在实际的程序设计中使用得更多的是动态SQL语句,因而在这一节中将重点介绍如何给动态的SQL语句的参数附值,以及如何在应用程序中灵活的使用SQL语句。
使用动态SQL语句中的参数就需要设置dataset的parameters()集合,一般可以通过如下的方式给它赋值:
利用Studio为参数赋值:
具体方法:选中dataset的parameters集合

图表 29
单击左侧的 ![]() 图标添加参数。
图标添加参数。
例如在DBDataset的sql属性中设置如下的SQL语句:
select * from employee where dept_id=:dept_id |
DBDataset的datasource属性为doradosample,其中的dept_id为参数变量。在上图的parameters集合设定视图中我们可以给相关的参数赋值。
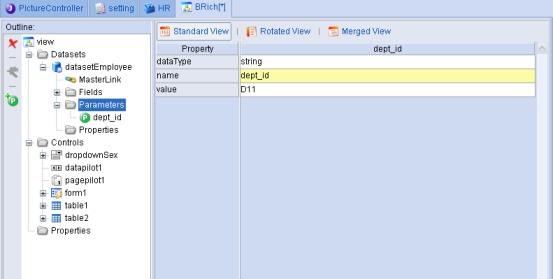
图表 30
这样DBDataset的sql就准备好了,并且其中的参数也被赋给了动态的SQL语句中的相应参数。此时如果我们执行查询,dataset就可以获取相关的数据。
通过Studio为parameters赋值,这种方式缺乏灵活性,在实际应用中用的较少,在某些情况下我们可以通过配合dorado提供的EL表达式增加studio配置的灵活性。参见EL表达式。
另外在实际应用中程序设计人员还希望用更灵活方便的方式为参数赋值,那就是接下来要介绍的另一种途径。
在运行过程中,通过程序为参数赋值
由于展现中间件的AJAX特性,我们通常会在两种情境下为参数赋值
服务器端赋值
Dataset对象拥有一个参数集合parameters(),它在设计时可以通过Studio定义,在程序运行的过程中也可以用,并且可以动态建立。当为Dataset设定动态带参数的sql语句时,dataset会自动地根据动态sql建立parameters()中的参数。
例如SQL语句:
Select * from employee where dept_id=:dept_id and sex=:sex |
对于上述的SQL语句,可以利用dataset的parameters()集合为参数赋值
dataset.parameters().setString("dept_id", "D11"); |
上述的语句就是把"D11"赋给参数dept_id,true赋给参数sex。
也可以用以下的方式赋值:
ParameterSet params = dataset.parameters(); |
另外参数也支持按顺序赋值,例如:
ParameterSet params = dataset.parameters(); |
客户端JS赋值
在dorado的客户端,我们也可以通过如下的方式给一个dataset的参数赋值:
dataset.parameters().setValue("dept_id", "D11"); |
或
var params = dataset.parameters(); |
使用MasterLink为参数赋值
在上述的两种方法中都有一个共同的特点是:在为各参数赋值时,必须事先知道个参数对应的具体参数值。而在具体的数据库应用中,有些参数值通常是无法确定的,例如参数的值来自另一个查询结果。对于这种情况,dorado提供了MasterLink属性动态的为动态的SQL语句赋值的方法。在SQL语句中尚存在没有赋值的参数时,dataset会自动地检查MasterLink的设置。如果为MasterLink属性定义了属性值,dataset就会从该属性值配置中查找另一个dataset的相关参数值,并且匹配到当前dataset的参数集合中。
下面就是创建动态SQL语句的实现方法:
datasetDept
<Dataset id="datasetDept" type="Wrapper" wrappedType="Sql" dataSource="doradosample" originTable="dept"> |
datasetEmployee
<Dataset id="datasetEmployee" type="Wrapper" wrappedType="Sql" dataSource="doradosample" originTable="employee"> |
给datasetEmployee添加MasterLink属性
属性 |
说明 |
masterDataset |
对应参数的数据源 |
masterKeyFields |
从参数数据源中获取数据的对应字段列表,多个字段使用逗号分割 |
detailKeyParameters |
为当前dataset的动态参数赋值时对应参数名称的列表,多个参数使用逗号分割 |
添加MasterLink之后,dataset的定义如下:
<Dataset id="datasetEmployee" type="Wrapper" wrappedType="Sql" dataSource="doradosample" originTable="employee"> |
datasetEmployee的动态SQL语句中的:dept_id参数在程序设计中没有给它赋值。当该应用程序运行时,dataset会自动地到masterDataset的datasetDept中查找dept_id值并且使用detailKeyParameters定义的dept_id作为datasetEmployee的dept_id参数赋值。如下图:
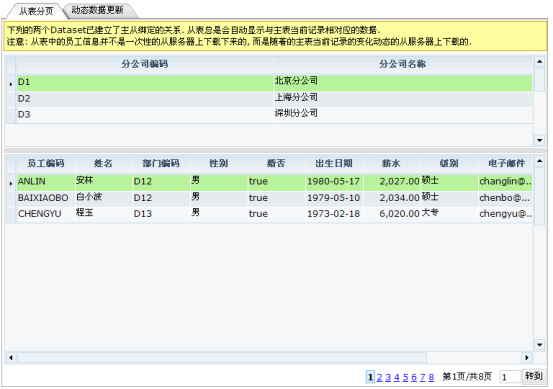
图表 31
当部门表移动记录指针时,参数:dept_id的值也会随之改变。而参数:dept_id的值发生改变时,datasetEmployee中的动态SQL会根据新的参数重新查询,从数据库中取出相应的员工列表数据。这也是我们常见的主从表应用的实现。
临时字段
有时候为了完成应用程序所期望的工作,常常需要在数据库表现有字段的基础上增加一些自定义的字段。这些字段并不是数据库表中实际存在的字段,它们常常是根据数据库表中的其它字段动态计算出来的或仅仅为了页面表现的需要而特殊添加的。因此它们被称为临时字段。
例如合同管理中的总金额字段,该字段为产品单价与产品数量的合计值,在dataset的添加字段
<Field name="sum" type="Dummy" dataType="float" readOnly="true" label="总金额" supportsSum="true"> |
在Properties Inspector窗口中选择View根节点,并选择Events Inspector面板,双击onDatasetsPrepared事件,为dataset添加如下代码:
datasetContractItems.disableControls(); |
完成上述步骤后,查看如下的运行效果:

图表 32
RetrieveAfterUpdate
部分数据库的设计中,对数据库表的某些字段提供系统级的自动处理功能,例如SQLServer以及MySQL等类型数据库的主键自增长功能。在dataset中新增的record对象在更新到数据库之前,自增长的关键字都为空,或没有具体的意义。而主键的实际值要在更新数据库之后才能拿到,很多技术人员喜欢在数据更新之后使用dataset的flushData重新获取数据库中的主键信息,这种处理方式相对来说比较消耗系统的性能,flushData会自动清理dataset中的所有数据,并重新查询数据库。这种处理方式尤其是在dataset的pageSize较大时,消耗的性能更为显著。这时候我们就可以利用dataset的RetrieveAfterUpdate功能,让dataset自动根据内部包含的数据获取相关的主键值。这种做法的好处是,我们不需要重新查询所有的数据,dataset会在一次更新中完成所有的动作。RetrieveAfterUpdate为true的dataset对象在更新数据库之后,dataset会自动判断自身新增记录,并从数据库中获取相关自动生成的主键值。很显然这种处理方式在性能上会比flushData大有提高。只是在使用RetrieveAfterUpdate方法的时候要注意,部分数据库并不支持RetrieveAfterUpdate操作。该属性与数据库本身提供的JDBC驱动有关。在Dorado的SampleCenter中有一个很好的演示该功能的例子,
http://61.151.239.187/dorado5/new-feature/new-dataset.jsp注意其中的"动态数据更新"的演示,在执行提交的过程中Dataset可以直接获得那些在服务端产生的新数据。
{kind=link}