动态数据下载dorado的另一种AJAX请求,在发出请求时,我们可以设定请求的参数,以及最终要激活的远程方法名称,而在服务层远程方法的内部就可以根据接收到的参数决定给客户端返回什么数据,返回的数据都是一种二维结构的信息,在dorado的POJO编程模式中,返回的结果可以是一个bean或一个包含bean的collection结构的对象。在很多情况下这种动态数据下载就是一种数据查询。
主要实现方法
dorado中的动态数据下载一般都交给dataset完成,体现在方法调用上,具体的说就是dataset的三个方法:
loadData():根据数据集当前的属性、参数设置,如pageSize、pageIndex等属性从服务器端下载数据;
loadPage(int pageIndex):下载指定页的数据到数据集中;
flushData():重新从服务器端下载数据集的数据,与loadData不同,flushData方法会先清空本地的缓存数据,再下载数据;
服务器如何响应这些请求
dorado动态数据下载在实际使用中不一定需要我们直接调用上述dataset的三个方法,有时候我们会通过一些其它的组件或技术辅助完成动态数据下载相关的参数设定,远程方法请求和数据刷新处理等工作。在介绍这些工作之前,我们必须先了解服务器端如何响应动态数据下载的请求,一般情况下我们都是通过dataset的监听器或视图模型实现类提供的动态数据下载监听函数响应请求。
Listener监听器
listener的处理与运行机制我们已经在上文中专门论述过,使用listener响应dataset的动态数据下载请求,我们可以通过其beforeLoadData()方法或afterLoadData()方法。
如:
public boolean beforeLoadData(Dataset dataset) throws Exception {
ParameterSet parameters = dataset.parameters();
dataset.insertRecord();
dataset.setString("id", "ANLIN");
dataset.setString("name", "安林");
dataset.setBoolean("sex", true);
dataset.setDouble("salary", 3000.00);
dataset.setString("degree", "硕士");
return false;
}
其中的代码不难理解,就是当listener侦听到dataset的分批数据下载动作并触发beforeLoadData方法时,我们通过insertRecord向dataset中添加一条新的记录。其中最后一行代码,通过返回false值通知dataset表示listener已经完成了数据加载工作,不必执行后续动作,如listener的afterLoadData。另外在以上代码中我们还注意到定义了一个ParameterSet的变量,由于客户端发出批量数据下载请求时,会将相关的请求参数信息收集到dataset的parameters()集合中,所以beforeLoadData()方法中的parameters变量就是用来获取获取客户端发出动态数据下载的相关参数值。
ParameterSet对象是dorado当中的一个基本参数集合对象,通过它我们可以使用索引位置或参数名方便的进行存取,如代码:
ParameterSet parameters = dataset.parameters();
String name = parameters.getString("name");
String id = parameters.getString(0);
parameters.setString(3, "本科");
详细内容可参考Server-API中关于ParameterSet一节。
实现类的监听方法
除了可以通过listener监听dataset的分批数据下载请求,视图模型实现类也提供了一个专门的函数用以响应该请求:
void doLoadData(ViewDataset dataset):当客户端的dataset发出数据分批下载请求时,会自动激活实现类的doLoadData()方法,其中参数dataset就是发出请求的dataset。与监听器不一样的是,listener一般是为某一个dataset提供服务,而doLoadData()方法却是会为视图模型中的多个dataset提供服务,为了使我们的逻辑代码专门为指定dataset提供服务,在代码编写的时候一定要记得做id的判断,如:
protected void doLoadData(ViewDataset dataset) throws Exception {
if ("datasetEmployee".equals(dataset.getId())){
dataset.insertRecord();
dataset.insertRecord();
dataset.setString("id", "ANLIN");
dataset.setString("name", "安林");
dataset.setBoolean("sex", true);
dataset.setDouble("salary", 3000.00);
dataset.setString("degree", "硕士");
}else{
super.doLoadData(dataset);
}
}
代码中super.doLoadData(dataset)代码,表示允许dataset根据自身的配置执行默认的数据加载工作,如Sql类型的,或通过listener实现数据加载的。由于datasetEmployee已经由该处的代码实现数据初始化,因此就可以不再执行super.doLoadData()方法,该处需要注意不要随便的屏蔽super.doLoadData()方法。因为往往一个视图模型中的dataset不止一个。如果被我们屏蔽执行会导致其他的dataset无法实现数据加载工作。
相关组件与技术
在了解了到服务器端响应dataset的数据分批下载请求的各种方法之后,我们再来看客户端如何发出这些请求,请求发出的方式有哪些类型,因为dorado动态数据下载在实际使用中不一定需要我们直接调用上述dataset的三个方法,有时候我们会通过一些其它的组件或技术辅助完成动态数据下载相关的参数设定,远程方法请求和数据刷新处理等工作。下面我们分别就每一种处理技术详细了解其处理办法。
QueryCommand
分批数据下载的一种最基础的表现形式就如下图:
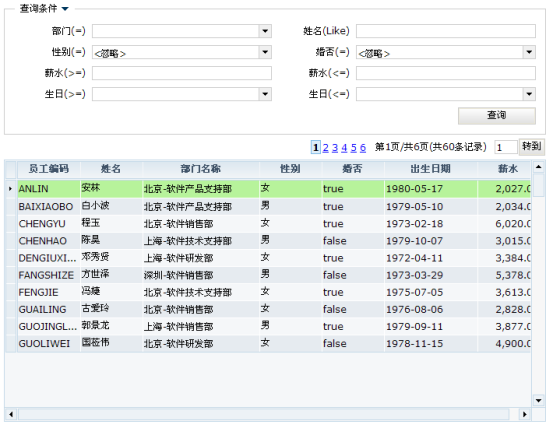
在上图中,用户可以在查询条件区域输入各种查询信息,并最后单击查询按钮。之后利用dataset的分批数据下载技术将查询条件作为远程方法的请求参数上传,在远程方法中再将查询条件值取出,执行查询,并将查询结果返回。由于这是一种AJAX技术,因此用户就可以不用刷新页面,直接在下方的表格中看到查询结果。
具体实现过程代码示例:
- 按钮单击事件中收集用户输入的值;
范例代码如下:
datasetEmployee.parameters().setValue("salary1", editorSalary1.value);
datasetEmployee.parameters().setValue("salary2", editorSalary2.value);
其中editorSalary1与editorSalary2为上图中用户输入的薪水查寻范围对应的两个编辑框对象。将取出的值收集到dataset的parameters()对象中。该对象最终会在listener中使用。
调用dataset的flushData方法;
datasetEmployee.parameters().setValue("salary1", editorSalary1.value); datasetEmployee.parameters().setValue("salary2", editorSalary2.value); datasetEmployee.flushData();在代码当中激活分批数据下载动作,使得服务器来响应该请求。
- 在listener中定义beforeLoadData方法;
给datasetEmployee添加一个listener并定义其中的beforeLoadData()方法。处理代码如下:
public boolean beforeLoadData(Dataset dataset) throws Exception {
ParameterSet parameters = dataset.parameters();
double salary1 = parameters.getDouble("salary1");
double salary2 = parameters.getDouble("salary2");
Connection conn = ConnectionHelper.getConnection("HR");
PreparedStatement pst = conn
.prepareStatement("select * from employee where salary>? and salary<?");
pst.setDouble(1, salary1);
pst.setDouble(2, salary2);
ResultSet rs = pst.executeQuery();
while (rs.next()) {
dataset.insertRecord();
dataset.setString("id", rs.getString("id"));
dataset.setString("name", rs.getString("name"));
dataset.setBoolean("sex", rs.getBoolean("sex"));
dataset.setDouble("salary", rs.getDouble("salary"));
dataset.setString("degree", rs.getString("degree"));
}
rs.close();
pst.close();
conn.close();
return false;
}
其中的代码并不难理解,ConnectionHelper已经在数据库访问对象中说明过,主要用于获取一个已经配置好的Connection对象。剩余的代码都非常容易理解,分片段如下:
获取用户输入的薪水范围查询值代码:
ParameterSet parameters = dataset.parameters();
double salary1 = parameters.getDouble("salary1");
double salary2 = parameters.getDouble("salary2");
使用PreparedStatement执行查询:
PreparedStatement pst = conn.prepareStatement("select * from employee where salary>? and salary<?");
pst.setDouble(1, salary1);
pst.setDouble(2, salary2);
ResultSet rs = pst.executeQuery();
将ResultSet中的数据导入Dataset中:
while(rs.next()){
dataset.insertRecord();
dataset.setString("id", rs.getString("id"));
dataset.setString("name", rs.getString("name"));
dataset.setBoolean("sex", rs.getBoolean("sex"));
dataset.setDouble("salary", rs.getDouble("salary"));
dataset.setString("degree", rs.getString("degree"));
}
设定beforeLoadData方法的返回值为false(含义参考Listener监听器部分):
return false;
以上内容就是一个查询的基本处理过程。
QueryCommand是一个用于协助开发人员完成查询处理过程中的第一个步骤-收集用户输入的查询条件。
在大量的查询开发中我们会发现有时候查询条件的数量是相当多的,如果我们大量的采用dataset.parameters().setValue()这种方法,会造成页面代码冗余性非常高。
如果采用QueryCommand实现开发则需要做如下的调整:
将用户要输入的查询条件全部定义在dorado的一个FormDataset或CustomDataset中。dataset的字段名与查询使用的参数名保持一致。如上例我们可以定义一个FormDataset,并添加两个字段salary1,salary2:
<Dataset type="Form" id="datasetCondition"> <Fields> <Field name="salary1" dataType="double"></Field> <Field name="salary2" dataType="double"></Field> </Fields> </Dataset>
设定页面查询条件区域编辑框全部绑定到datasetCondition中:
<d:TextEditor id="editorSalary1" dataset="datasetCondition" field="salary1"/> <d:TextEditor id="editorSalary2" dataset="datasetCondition" field="salary2"/>
添加QueryCommand对象,并设定其conditionDataset为查询条件datasetCondition,queryDataset为最终执行数据分批下载的datasetEmployee。

最后我们只要将按钮的单击事件代码调整为:
commandQuery.execute();
commandQuery的execute()方法就会自动的根据系统配置完成前面的参数收集工作。
另外QueryCommand对象还提供了一个默认的功能,由于QueryCommand对象继承自Command,所以自动拥有parameters参数集合,在QueryCommand执行execute()方法时,参数收集工作中的参数值来源除了conditonDataset属性对应的查询条件dataset外,还包括QueryCommand的parameters()集合。并且收集的顺序为:
第一步收集conditionDataset;
第二步收集QueryCommand的parameters();
如果有相同参数,以最后执行的赋值代码为准。
MasterLink
MasterLink是dataset分批数据下载技术的另一种应用,最常见的一种场景是明细表数据显示,如下图:

上图中,当我们选择不同的分公司时,可以看到下方员工表格的数据会显示相应的分公司的员工列表。而在这个过程中是完全无需页面刷新的。
如果采用上文我们对于dataset的分批数据下载技术,我们可以这么实现:
当分公司表格选择不同数据行的时候或得分公司编号信息;
Datatable在表格行发生变化的时候会引起绑定dataset触发afterScroll事件,该事件提供了一个record参数,该参数表示当前行对应的record记录对象,因此该处的代码我们就利用这个事件获取分公司编号信息:var branched = datasetBranch.getValue("branch_id");将分公司编号信息作为员工列表绑定的dataset的参数信息储存;
在步骤一种获取到branchId信息之后,我们就可以设定员工数据集的参数信息了:datasetEmployee.parameters().setValue("branched", branchId);利用dataset的远程方法调用机制触发listener或视图模型实现类的侦听方法;
调用dataset的flushData()方法:datasetEmployee.flushData();
在侦听方法中获取dataset参数中的分公司编号信息;
ParameterSet parameters = dataset.parameters(); String branchId = parameters.getString("branchId");利用分公司编号信息查询关联的员工数据,并返回;
public boolean beforeLoadData(Dataset dataset) throws Exception { String sql = "select employee.* from employee, dept where employee.dept_id=dept.dept_id and dept.branch_id=?"; Connection conn = ConnectionHelper.getConnection("HR"); PreparedStatement pst = conn.prepareStatement(sql); pst.setString(1, branchId); ResultSet rs = pst.executeQuery(); while (rs.next()) { dataset.insertRecord(); dataset.setString("employee_id", rs.getString("employee_id")); dataset.setString("dept_id", rs.getString("dept_id")); dataset.setString("employee_name", rs.getString("employee_name")); dataset.setBoolean("employee_id", rs.getBoolean("sex")); dataset.setDate("birthday", rs.getDate("birthday")); dataset.setBoolean("married", rs.getBoolean("married")); dataset.setDouble("salary", rs.getDouble("salary")); dataset.setString("degree", rs.getString("degree")); dataset.setString("email", rs.getString("email")); } rs.close(); pst.close(); conn.close(); dataset.moveFirst(); // 由于代码已经通过rs将数据放在dataset中,应此返回false. return false; }
具体范例可以参考配套工程中master-detail。
Master-detail相关文件为:
MasterDetail.view.xml,
ajax. EmployeeDatasetListener.java;
master_detail.jsp;
以上功能开发如果利用dorado的MasterLink技术可以大大简化客户端的开发。使用方法如下:
datasetEmployee添加masterLink的申明:
<MasterLink masterKeyFields="branch_id" masterDataset="datasetBranch" detailKeyParameters="branchId"/>
运行时masterLink所作的工作就会根据配置执行如下的动作:datasetEmployee的主表为datasetBranch,对应主表的关键字段为branch_id,系统运行时会自动地从datasetBranch中收集branch_id的值,并保存到datasetEmployee的 parameters(),保存时设定远程方法接受分公司编号信息的参数名为branchId,然后由datasetEmployee向服务器发出分批数据下载请求。这些工作就相当于前文中的1,2,3步骤。
具体范例参考配套工程中的master-link1。
master-link1相关文件:
MasterLink1.view.xml;
ajax. EmployeeDatasetListener.java;
master_link1.jsp;
在实际项目开发中,除了以上范例提到的主从明细表格展现方式之外还有更多的展现方式,如数据绑定树:
下拉列表: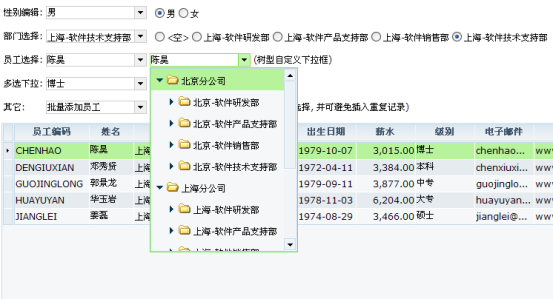
借助你丰富的想象力,可以利用MasterLink技术实现更多的展现效果和衍生出更多的使用技巧。