简述
DataTree是继承与Tree的树,在Tree基本功能和处理技术原理的基础上提供了Dataset绑定机制,便于应用开发的时候提供开发人员更大的便利性的一个组件。
使用DataTree相对于Tree来说的方便之处在于:
- Tree的初始化过程更为简洁,JS代码量大大减少;
- 实现数据延迟加载的方式大大简化;
- 利用RecordTreeNode对象的Record绑定机制使得树节点包含的信息量更为丰富;
- 在需要对树节点大量修改操作的界面中可以大大减少AJAX的交互次数,提高整体的维护效率;
使用
在DataTree中引入TreeLevel概念,用以实现与Dataset的绑定处理。对于TreeNode中的lable属性在TreeLevel中使用labelField属性进行设置,如下代码:
SampleTreeLevel treeLevel = new SimpleTreeLevel(); |
在我们讨论Tree开发的时候还提到DefaultTreeNode的几个特性:
菜单树功能;
Icon图标设定;
复选框功能;
这些功能在DataTree中也提供了同样的支持,并也同时提供了Dataset绑定机制,对应的属性比较列表为:
功能 |
DefaultTreeNode |
TreeLevel |
图标 |
icon/expandedIcon |
iconField/expandedIconField |
选中状态 |
checked |
checkedField |
标题 |
label |
labelField |
path |
path |
pathField |
通过以上的与dataset相关的属性,使得对节点的大部分设置我们都可以通过dataset提供的信息实现。
前面提到的TreeLevel目前是一个基类,在DataTree使用中一般是通过两个子类完成设计和开发的:SimpleTreelevel和RecursiveTreeLevel。
SimpleTreelevel利用绑定的dataset中包含的数据,自动构造树的节点。
RecursiveTreeLevel则利用绑定的dataset构造具有递归关系的树节点对象。
这两个对象都可以直接添加到Tree中,在一种TreeLevel中也可以同时包含多个平级的TreeLevel对象,从而实现复杂树的构造。
另外与Tree中默认树节点的类型为DefaultTreeNode不同,DataTree中包含的默认树节点的类型为RecordTreeNode。该类型的树节点是与Dataset绑定的,提供getRecord()方法获取绑定的Record对象。
由于TreeLevel处理技术中涉及到Dataset相关部分,应此在使用DataTree的时候,需要您先掌握Dataset的相关技术:查询技术、分页技术、flushData处理技术以及MasterLink处理技术。
SimpleTreeLevel使用说明
SimpleTreeLevel使用时需要将其与Dataset绑定的相关属性设置好,Tree就能自动的利用Dataset中包含的数据实现树节点的构造,如我们实现一颗分公司的树,在ViewModel中定义好datasetBranch后,只要在DataTree中定义一个SimpleTreeLevel对象,并定义其中的几个关键属性即可,如下截图:
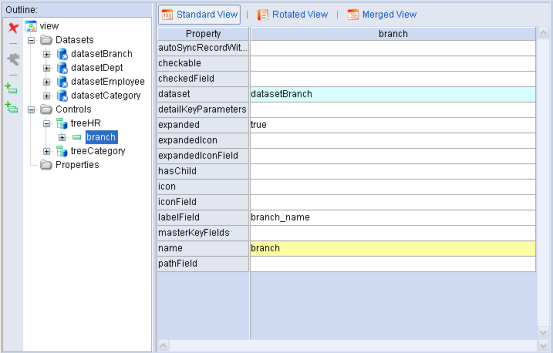
其中名称为branch的SimpleTreeLevel对象中的dataset, labelField中属性设置,使其与datasetBranch关联。这样就可以得到如下的一颗树:

如果要在上述范例的基础上实现组织结构树的定义,则我们需要定义树中节点的父子关系,在Tree使用详解中我们可以通过TreeNode提供的addNode方法实现树节点的上下级关系设定。而当我们使用SimpleTreeLevel技术设计树结构时,也支持我们实现父子关系,父子关系的实现我们可以利用数据绑定功能,利用dataset的MasterLink技术实现,当然也可以用另一个办法,利用SimpleTreeLevel本身提供的父子关系描述实现。关键属性有:masterKeyFields, detailKeyParameters。
两种方式的实现下面我们详细说明:
方式一:通过MasterLink属性设定
如果我们已经使用的dataset的MasterLink属性设置好dataset之间的主从关系,如datasetBranch, datasetDept, datasetEmployee。
则在定义DataTree时,我们就可以直接定义三个SimpleTreeLevel对象,并设置好节点的包含关系以及与dataset的绑定的属性设定,如:
<Control id="treeHR" type="DataTree"> |
名称为branch的SimpleTreeLevel包含名称为dept的SimpleTreeLevel对象,绑定的dataset相互之间拥有主从关系。则SimpleTreeLevel在运行时会自动的依据主从关系生成树节点。这样我们就可以很容易的实现如下的树结构:

在以上的设计中TreeLevel相互之前只定义包含关系,数据的关联特性都是通过dataset的MasterLink属性描述。
MasterLink定义的详细说明请参考<<快速入门一.doc >>2.0版本、<<dorado 5 用户指南 v1.1.doc>>。
方式二:通过masterKeyFields,detailKeyParameters属性设定明细关系
上文我们利用Dataset的MasterLink特性实现树中上下层节点的明细关系,另外我们也可以利用SimpleTreeLevel的masterKeyFields以及detailKeyParameters属性实现明细关系。同样是上例,我们可以在设计dataset的时候不做MasterLink属性的设置,将相关属性清空,然后我们用如下的代码设置不同TreeLevel中的masterKeyFields与detailKeyParameters设定:
<Control id="tree1" type="DataTree"> |
以上代码中蓝色粗体内容就是新增的xml配置代码。对比MasterLink代码我们可以发现其中的设置是具有相同性的,看datasetDept的MasterLink代码:
<MasterLink masterDataset="datasetBranch" masterKeyFields="BRANCH_ID" detailKeyParameters="BRANCH_ID" /> |
看datasetEmployee的MasterLink代码:
<MasterLink masterDataset="datasetDept" masterKeyFields="DEPT_ID" detailKeyParameters="DEPT_ID" /> |
除了masterDataset属性没有直接在SimpleTreeLevel的配置中得到体现外,另两个属性的设置是完全一模一样的。而masterDataset属性,在SimpleTreeLevel也很容易取得,只要按照TreeLevel在DataTree中的层次,向上找到父TreeLevel的dataset属性即可,应此在SimpleTreeLevel中就不必拥有这个属性。
通过以上的这种方式实现DataTree与我们在方式一中通过MasterLink技术实现的页面效果一样的。
在SimpleTreeLevel中我们通过节点包含方式让不同的SimpleTreeLevel对象产生关系,这种包含关系的设定在设计时,我们既可以在一个SimpleTreeLevel包含一个到多个SimpleTreeLevel对象,也可以在SimpleTreeLevel对象同时中包含SimpleTreeLevel对象和RecursiveTreeLevel对象。从而可以使树具有更多的灵活性。RecursiveTreeLevel类型的对象我们在下一节详细说明。
RecursiveTreeLevel使用说明
RecursiveTreeLevel用于实现具有递归关系的树节点,同SimpleTreeLevel对象一样,RecursiveTreeLevel也用对象绑定技术进行设计和开发。
例如对于如下的表结构,如果我们希望将其中的数据变成具有上下级关系的树节点展示给用户:
id |
label |
parentId |
001 |
浙江 |
|
002 |
河北 |
|
003 |
山西 |
|
00101 |
衢州 |
001 |
00201 |
石家庄 |
002 |
00301 |
太原 |
003 |
0010101 |
常山 |
00101 |
0010102 |
开化 |
00101 |
0010103 |
龙游 |
00101 |
0010104 |
衢县 |
00101 |
001010401 |
衢化 |
0010104 |
仔细观察上表格中的数据,我们可以看到其中数据之间的关系是通过parentId字段关联的。对于这种类型的数据在DataTree的设计中称做递归数据。利用RecursiveTreeLevel我们可以很容易的描述和定义这种类型的树节点。
首先当然得定义一个支持parentId查询的dataset对象。并且保证当parentId为空时查出的数据是上表中的parentId的数据。定义好这个dataset之后,我们就可以这么设计RecursiveTreeLevel对象。
RecursiveTreeLevel对象与SimpleTreeLevel对象基本一致,是继承SimpleTreeLevel对象的新对象,提供了两个扩展属性recursiveKepFields, recursiveKeyParameters。当我们展开一个RecursiveTreeLevel类型的RecordTreeNode节点时,Tree会自动的根据这两个属性的设定以及该节点所绑定的dataset对象通过服务器获取新的数据,并根据新获得的数据构造其子节点,新生成的子节点的类型依然是RecursiveTreeLevel,依然绑定其父节点对应的dataset对象。并且可以继续在子节点上展开,Tree再次判断新生成的子节点的recursiveKepFields, recursiveKeyParameters属性对dataset执行新的数据请求,从而递归生成下一级子节点的数据。
使用RecursiveTreeLevel实现树节点时的一个好处是由于树节点在展开的时候才动态生成,应此在树的初始化的时候并不需要下载所有的数据,从而减少后台数据查询方面的开销,而提高树的展现效率。
上述表格中的数据如果要以 RecursiveTreeLevel开发,则定义dataset如下(dataset的设定此处省略,参考dataset部分的参数使用和查询机制):
<Dataset id="datasetUnit" .........> |
依据dataset的设定,RecursiveTreeLevel设定如下:
<TreeLevel |
这样我们就可以获得我们想要的树了:

RecordTreeNode特性说明
DataTree对象中的所有节点类型为RecordTreeNode,这与Tree中的节点对象DefaultTreeNode不同。RecordTreeNode对象会自动绑定Dataset中的一个Record对象,我们可以通过RecordTreeNode的getRecord方法获得其所绑定的记录对象。
例如在范例:http://www.bstek.com/dorado5/skills/tree/datatree.jsp 中员工性别不同时,树节点的图标可以不一样。在该例子中我们利用DataTree的onRefreshNode事件实现:
if (node.getLevel() > 2) { |
代码中就利用了node的getRecord()方法获取节点绑定的Record对象的sex值,动态设定node的icon。
再看另一个应用:http://www.bstek.com/dorado5/skills/tree/product-tree.jsp 在该应用中产品分类发生移动后我们需要调整该分类的父分类信息,代码如下(原范例简化后得到):
var draggingRecord = draggingObject.getRecord(); |
范例代码中根据绑定的Record对象修改被移动的树节点对应的parent_id信息。
另外由于RecordTreeNode是tree根据自身的RecursiveTreeLevel设定生成,在RecordTreeNode中还提供了getTreeLevel()方法,便于我们知道当前节点的RecursiveTreeLevel特性,同样是上述的产品树中,我们要避免将产品分类树节点移动到产品叶子节点中,则我们在Tree的onDragOver事件中定义了如下的代码:
var draggingLevel = draggingObject.getTreeLevel().getName(); |
targetLevel == "category");* |
|---|
代码中根据TreeLevel的name属性是否为root或category来决定是否允许入坞操作。
常用技巧
动态树
在DataTable的使用中,我们可以利用Dataset提供的查询和flushData以及翻页功能动态灵活的改变表格中的数据。
对于DataTree来说也可以实现,但是处理稍有不同。dorado中的数据树可以自动监听绑定的Dataset中记录的数据变化和删除等事件,但不能自动处理新增的操作(包括利用flushData()等操作从服务端新下载的记录)。因此当我们希望在数据树中能够出现与新增记录绑定的节点时必须手工进行添加。
例如当我们利用dataset执行flushData操作时,从而使得DataTree中的rootNode节点发生变化的时候,则需要利用Tree的addRootNode()方法构造树的rootNode节点对象,代码如下:
datasetDept.disableControls(); |
如果节点类型不是rootNode,则我们直接利用addNode方法实现添加树节点即可。
范例查看:
树节点定位
利用setCurrentNodeByRecord()
通常情况下树节点的定位我们可以直接利用DataTree中的setCurrentNodeByRecord()方法实现。该方法的声明可以参考下文中主要方法说明中的setCurrentNodeByRecord()部分。
利用expandNode()遍历Tree(不推荐)
当时在更多的情况下,由于树的延迟加载特性,树节点还没有真正的在客户端初始化,我们通过setCurrentNodeByRecord()方法是无法找到对应的树节点的。应此我们必须一层一层的展开树节点并进行定位处理,例如如下的范例代码:
function findNode(parentNode, orgCode){ |
以上的代码中通过一个递归函数findNode查找符合条件的树节点对象。在findNode函数的基础上,我们就可以利用如下的代码实现树节点定位:
var orgCode = "D11"; |
以上方法完全可以满足我们的要求,但是在实际开发中如果树的结构比较复杂,节点对象又比较多,则对一颗树在客户端进行遍历会产生很多的延迟数据加载动作,造成极大的网络流量。以及加重了客户端的数据负载。例如树的层次有5层,每一个字层如果都有100个子节点,则如果查询的恰好是树的最后一个叶子节点,则查询会导致树初始化100*100*100*100个数节点,产生100*100*100*100次的客户服务器的数据交互动作。显然效率是极其低下。
利用RPCCommand辅助定位(推荐)
更为妥善的处理方式是,findNode方法调整到服务器,用Java代码实现。并利用ViewProperties返回查询结果,我们将查询结果数据设计为树的路径描述字符串,例如:"北京分公司:北京分公司-软件研发部:刘远力",客户端再利用这个字符串expand树中的一部分节点。如下的代码范例:
function findNode(parentNode, orgCode){ |
如果采用这种方式实现树的节点定位,则树最多初始化500个节点,执行5次(4次数据延迟加载和一次RPCCommand的RPC请求)客户端与服务器端的数据交互。与前述的方式效率完全不一样,大大优化了树节点定位的效率。
树节点拖拽
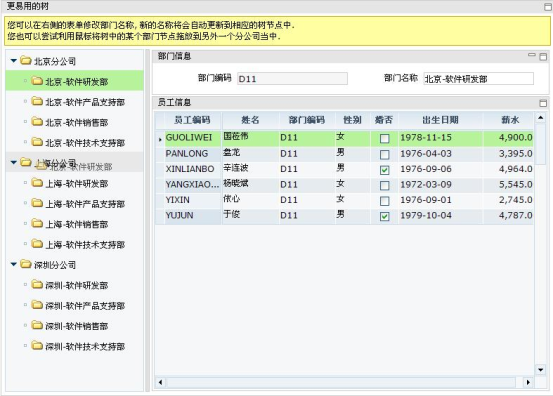
DataTree支持节点拖拽操作,只要设置Tree的draggable为"true",树就允许拖拽操作了。我们看下图:
图表 22
当设置tree的draggable为tree之后,我们就可以在上图的范例中实现树节点拖拽,例如我们将北京软件研发部从北京分公司移动到上海分公司。我们看一下数据库的branch表的结构:
Branch |
CREATE TABLE `branch` ( |
以及部门表的定义:
Dept |
CREATE TABLE `dept` ( |
从上两张表的神明可以看到,dept表拥有一个外键用以关联branch表。因此在上图的树节点拖拽操作中还拥有一个不可忽视的业务逻辑,就是要动态修改北京-软件研发部的branch_id信息。
实现这个功能我们可以利用tree的onDragEnd事件,onDragEnd事件的申明参考Tree中的节点拖拽事件说明部分:
在上图的范例中,发生onDragEnd事件时,其中的参数draggingObject参数就代表着被拖拽的北京软件研发部,targetObject就表示接受该节点的上海分公司。则我们就可以在onDragEnd事件中这么写代码:
var deptRecord = draggingObject.getRecord(); |
上述代码的作用是节点拖拽结束之后动态修改北京软件研发部节点对应的record对象的branch_id属性为上海分公司的branch_id。
另外我们也可以利用onDragBegin事件作特殊功能控制,例如通过onDragBegin事件决定节点是否允许被拖拽。如上例中我们不允许对分公司节点拖拽操作,则在onDragBegin中加入如下代码(onDragBegin事件的声明参考Tree中的节点拖拽事件说明):
return (draggingObject.getLevel() == 2); |
上面的代码通过判断认为只有被拖拽树节点的层次等级等于2的才允许拖拽。由于分公司节点在该页面的设计中处于第一层,所以如果此时draggingObject的层次为1时,系统就不允许拖拽操作。
关于树节点的拖拽操作还有一个重要的函数onDragOver(事件的声明参考Tree中的节点拖拽事件说明),例如上例如果深圳分公司不允许接受其他分公司移动过来的树节点,就可以通过如下的代码加以控制:
var record = targetObject.getRecord(); |
其中判断节点的分公司编号为D3表示为深圳分公司。则返回false不允许深圳分公司接受其他分公司的部门节点的移入动作。
在下拉框中显示DataTree
参考CustomDropDown的使用。
动态编程
所谓DataTree的动态编程,是希望提供一种非XML配置的方式用Java代码实现DataTree设计的工作。在使用DataTree动态编程的时候必须先了解DataTree的addTreeLevel方法:
public void addTreeLevel(TreeLevel level) |
该方法接收一个TreeLevle类型的对象,由于SimpleTreeLevel和RecursiveTreeLevel对象都是继承自TreeLevel的子类,应此该方法可以用以添加这两种类型的子类。
之后再通过SimpleTreeLevel和RecursiveTreeLevel两个java类的API参考文档,构造出应用需要的TreeLevel对象,并用addTreeLevel()添加到DataTree中。
以http://www.bstek.com/dorado5/skills/tree/datatree.jsp 为例,其中的两颗树分别是用RecursiveTreeLevel和SimpleTreelevel实现的。下面我们用代码创建这两个DataTree。
在视图模型实现类的initControl方法中实现treeHR的定义。代码如下:
protected void initControl(Control control) throws Exception {
|
对于使用RecursiveTreeLevel对象定义treeCategory对象也可以用如下代码实现:
protected void initControl(Control control) throws Exception {
|
主要属性说明
参考Tree的主要属性说明。
SimpleTreeLevel的基本属性
dataset
SimpleTreeLevel所绑定的dataset对象
autoSyncRecordWithDragging
前面在SimpleTreeLevel使用中我们提到过树节点上下级关系我们可以利用dataset的masterLink技术实现。在MasterLink技术中,dataset会自动的根据主表的变化维护其detailKeyFields属性代表的字段信息。
而当我们对于SimpleTreeLevel类型的树节点当从一个地方移动到另一个地方的时候,例如部门节点从一家分公司移动到另一家分公司时。我们也希望可以自动的维护detailKeyFields中的内容,则需要将autoSyncRecordWithDragging功能打开。MasterLink的detailKeyFields功能参考<<用户手册.doc>>中MasterLink部分。
checkedField
通过绑定Record记录对应checkedField字段对应的值设置复选框默认显示状态。如范例:http://www.bstek.com/dorado5/skills/tree/datatree.jsp 中复选框对象的checkedField绑定到datasetEmployee表的sex字段上。
配置代码如下:
<TreeLevel |
labelField
Tree的label数据绑定属性,树节点初始化时自动的将自身绑定的Record对象中取出lavelField对应的值作为Tree的label显示。
masterKeyFields, detailKeyParameters
这两个属性用于树节点上下层关系设定,当我们展开一个树节点时,如果其子节点是由TreeLevel定义的,则系统自动的依据子节点的masterKeyFields属性配置从当前节点所绑定的record对象中取出所有字段的值,并获取子节点对应的TreeLevel对象的detailKeyParameters属性,将这些值按照detailKeyParameters属性中的参数名称传入子节点对应的TreeLevel的dataset的parameters集合中。并利用dataset执行数据查询获取匹配的数据进而构造下一层子节点。
其使用方式在SimpleTreeLevel的使用说明中已经提及,参考理解。
masterKeyFields与detailKeyParameters都可以配置为多个变量,中间用逗号分割。
iconField,expandedIconField
图标设置相关的属性,TreeLevel中既有icon,expandedIcon属性也有iconField,expandedIconField属性。它们都是设定树节点图标相关的属性,其中iconField的属性设置优先于icon属性设置,expandedIconField属性设置优先于expandedIcon,如果同时设置则只有iconField与expandedIconField起作用。
pathField
在前文的Tree的页面导航功能说明中我们描述过TreeNode的path属性的作用。pathField的定义就是运行期系统可以自动的从RecordTreeNode对象所绑定的Record中取出pathField对应的数据作为path使用。
name
TreeLevel的名称,定义好name属性后,我们可以通过Tree的getTreeLevle(String name)方法获得TreeLevel对象。
其他属性
其他属性参考DefaultTreeNode的属性说明。
RecursiveTreeLevel的基本属性
masterKeyFields,detailKeyParameters
参考SimpleTreeLevel中masterKeyFields与detailKeyParameters属性的说明。
recursiveKeyFields, recursiveKeyParameters
recursiveKeyFields和recursiveKeyParameters的处理机制与masterKeyFields,detailKeyParameters的处理机制有一定的类似性。
这两个属性都用于递归层内部的树节点上下级关系设定,当我们展开一个RecursiveTreeLevel对象生成的树节点时,系统会自动的依据当前节点的masterKeyFields属性配置从当前节点所绑定的record对象中取出所有字段的值,并获取当前节点对应的detailKeyParameters属性配置,将这些值按照detailKeyParameters配置中的参数名称传入当前节点dataset的parameters集合中。并利用dataset执行数据查询获取匹配的数据进而构造下一级的子节点。
其使用方式在RecursiveTreeLevel的使用说明中已经提及,参考理解。
recursiveKeyFields与recursiveKeyParameters也支持多个变量设定,中间用逗号分割。
expandLevel
递归层默认展开的层次数。
其他属性
其它属性参考SimpleTreeLevel以及DefaultTreeNode属性说明。
主要事件说明
参考Tree的事件说明
主要方法说明
addTreeLevel()
DataTree提供addTreeLevel(TreeLevel level)方法添加一个根节点层。
findNodeByRecord()
findNodeByRecord(Record record)方法根据指定的record对象到树中查找匹配的记录。查找的时候该方法会遍历树中已经初始化过的所有子节点,直到找到符合条件的数据为止。
getTreeLevel()
在设计时,我们有可能在树的根目录中添加多个TreeLevel。在使用时,我们可以根据getTreeLevel(String name)获得指定的TreeLevel对象,其中参数name即TreeLevel的name属性。如果不存在则返回undefined。
getTreeLevels()
该方法用以获得Tree下所有的跟TreeLevel集合,返回集合以HashList结构提供。HashList的使用参考Client-API中的相关说明。
refreshNodeByRecord()
根据给定的record对象找到对应的树节点,并刷新该树节点。方法声明如下:
public void refreshNodeByRecord(Record record) |
该方法与findNodeByRecord(Record record)是配合使用的。
setCurrentNodeByRecord()
根据给定的Record对象查找对应的树节点对象,如果找到就将其设置为当前树的节点。方法声明如下:
public void setCurrentNodeByRecord(Record record) |
该方法与findNodeByRecord(Record record)是配合使用的。
CSS说明
请参考Tree的CSS说明部分