在UFLO2中简化了集群部署方式,对于我们开发好的应用来说,如果需要集群部署,需要做两件事情:一件是替换UFLO中默认基于内存的缓存服务;另一件就是配置一些集群参数。我们先来看看如何替换UFLO中默认基于内存的缓存服务。
替换缓存服务
要替换UFLO中默认基于内存的缓存服务,我们只需要编写一个com.bstek.uflo.service.CacheService接口实现类,并将其配置到Spring中即可。CacheService接口源码如下:
package com.bstek.uflo.service;
import java.util.Collection;
import com.bstek.uflo.expr.impl.ProcessMapContext;
import com.bstek.uflo.model.ProcessDefinition;
/**
* @author Jacky.gao
* @since 2016年12月9日
*/
public interface CacheService {
ProcessDefinition getProcessDefinition(long processId);
void putProcessDefinition(long processId,ProcessDefinition process);
boolean containsProcessDefinition(long processId);
Collection<ProcessDefinition> loadAllProcessDefinitions();
void removeProcessDefinition(long processId);
ProcessMapContext getContext(long processInstanceId);
void putContext(long processInstanceId,ProcessMapContext context);
void removeContext(long processInstanceId);
boolean containsContext(long processInstanceId);
}
在实现这个接口时,我们可以将所有的缓存信息存储到一个缓存服务器,比如Radis或MemoryCache等,然后将实现类开配置到Spring当中,这样UFLO在启动时即可检测到这个实现类的存在,从而替换其默认的放在内存中的缓存实现类。
下面是一个CacheService实现类,它连接了Redis将流程相关信息缓存到Redis服务器。
package test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Set;
import redis.clients.jedis.Jedis;
import com.bstek.uflo.expr.impl.ProcessMapContext;
import com.bstek.uflo.model.ProcessDefinition;
import com.bstek.uflo.service.CacheService;
/**
* @author Jacky.gao
* @since 2017年11月6日
*/
public class RedisCacheService implements CacheService {
private static final String PREFIX="UFLO_CAChe_";
private Jedis jedis=new Jedis("localhost");
@Override
public ProcessDefinition getProcessDefinition(long processId) {
if(!containsProcessDefinition(processId)){
return null;
}
String key=PREFIX+"PD_"+processId;
byte[] bytes=jedis.get(key.getBytes());
return (ProcessDefinition)SerializeUtil.unserialize(bytes);
}
@Override
public void putProcessDefinition(long processId, ProcessDefinition process) {
String key=PREFIX+"PD_"+processId;
jedis.set(key.getBytes(), SerializeUtil.serialize(process));
}
@Override
public boolean containsProcessDefinition(long processId) {
String key=PREFIX+"PD_"+processId;
return jedis.exists(key.getBytes());
}
@Override
public Collection<ProcessDefinition> loadAllProcessDefinitions() {
String key=PREFIX+"PD_*";
Set<byte[]> set=jedis.keys(key.getBytes());
List<ProcessDefinition> list=new ArrayList<ProcessDefinition>();
for(byte[] bytes:set){
ProcessDefinition pd=(ProcessDefinition)SerializeUtil.unserialize(bytes);
list.add(pd);
}
return list;
}
@Override
public void removeProcessDefinition(long processId) {
String key=PREFIX+"PD_"+processId;
jedis.del(key.getBytes());
}
@Override
public ProcessMapContext getContext(long processInstanceId) {
if(!containsContext(processInstanceId)){
return null;
}
String key=PREFIX+"PI_"+processInstanceId;
byte[] bytes=jedis.get(key.getBytes());
ProcessMapContext context=(ProcessMapContext)SerializeUtil.unserialize(bytes);
return context;
}
@Override
public void putContext(long processInstanceId, ProcessMapContext context) {
String key=PREFIX+"PI_"+processInstanceId;
jedis.set(key.getBytes(), SerializeUtil.serialize(context));
}
@Override
public void removeContext(long processInstanceId) {
String key=PREFIX+"PI_"+processInstanceId;
jedis.del(key.getBytes());
}
@Override
public boolean containsContext(long processInstanceId) {
String key=PREFIX+"PI_"+processInstanceId;
return jedis.exists(key.getBytes());
}
}
package test;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
/**
* @author Jacky.gao
* @since 2017年11月6日
*/
public class SerializeUtil {
public static byte[] serialize(Object object) {
ObjectOutputStream oos = null;
ByteArrayOutputStream baos = null;
try {
// 序列化
baos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(baos);
oos.writeObject(object);
byte[] bytes = baos.toByteArray();
return bytes;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static Object unserialize(byte[] bytes) {
ByteArrayInputStream bais = null;
try {
// 反序列化
bais = new ByteArrayInputStream(bytes);
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
配置集群参数
在UFLO中允许我们在任务节点上配置各种类型的提醒(任务到达提醒、过期提醒等),一旦我们配置了提醒,那么在产生提醒的任务时,UFLO会自动运行JOB引擎,在后台周期性执行这些提醒任务。在集群环境下,如果我们也使用了任务中的各种提醒,那么就需要在项目中配置一些集群参数,从而实现多个集群实例下,只有一个实例运行JOB引擎,同时一个实例的JOB引擎宕机后,其它实例能检测到,并继续运行JOB引擎,从而保证任务提醒功能的正确运行。
集群环境下,我们需要在应用当中添加一个名为“uflo.clusterInstanceNames”的参数,该参数的作用是用来指定当前集群实例的名字,实例名之间用“,”号分隔,比如“uflo.clusterInstanceNames=app1,app2,app3”,这就表示当前应用集群部署有三个实例,我们分别将其命名为app1,app2,app3,这个参数配置完成后,我们还需要在每个集群实例对应的appServer上配置一个名为“uflo.instanceName”的JVM参数,该参数配置好后,在当前appServer的应用中就可以通过System.getProperty("uflo.instanceName")方法获取到,需要注意的是“uflo.instanceName”参数的值与“uflo.clusterInstanceNames”属性的值需要对应起来,比如实例A上我们定义“uflo.instanceName”参数为"app1";实例B上我们定义“uflo.instanceName”参数为"app2";实例C上我们定义“uflo.instanceName”参数为"app3"。这样在部署到JOB引擎会首先在uflo.instanceName”参数为"app1"的实例A应用服务器上运行;如果实例A应用服务器因为某些原因宕机,那么实例B应用服务器将会继续运动JOB引擎,依次类推。
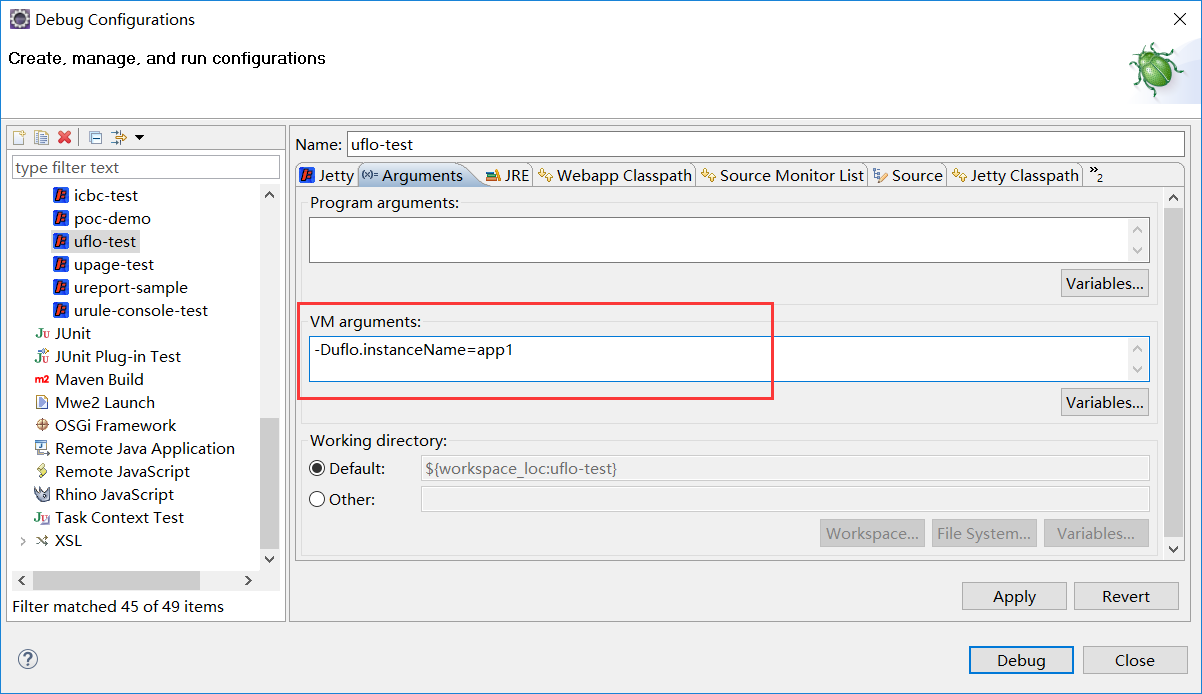
下图是配置在Eclipse中Jetty的JVM参数“uflo.instanceName”的配置方式:
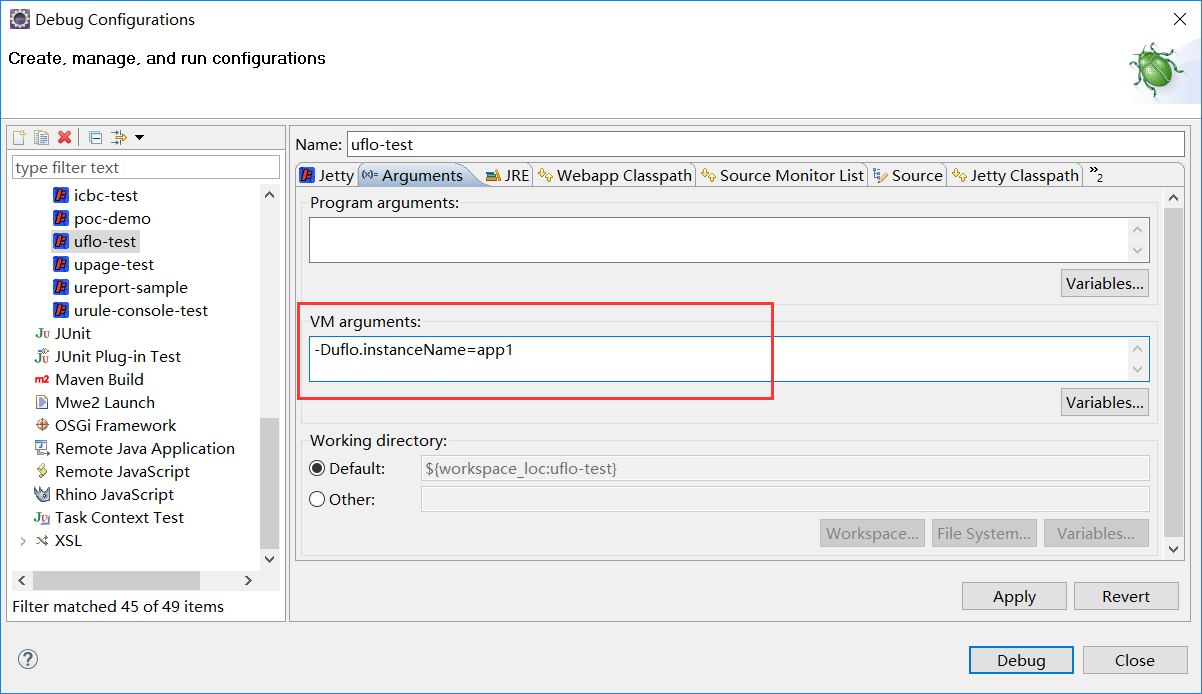
添加JVM参数需要以-D开头,所以上图中可以看到“uflo.instanceName”参数定义时写为-Duflo.instanceName=app1,表示定义一个JVM参数“uflo.instanceName”值为“app1”。
如果是采用Tomcat,那么可以切换到Tomcat安装目录下的bin目录,打开其中的catalina.bat文件(windows下Tomcat配置),查询"set JAVA_OPTS"字符串位置,在其后添加-Duflo.instanceName值即可,如下图:
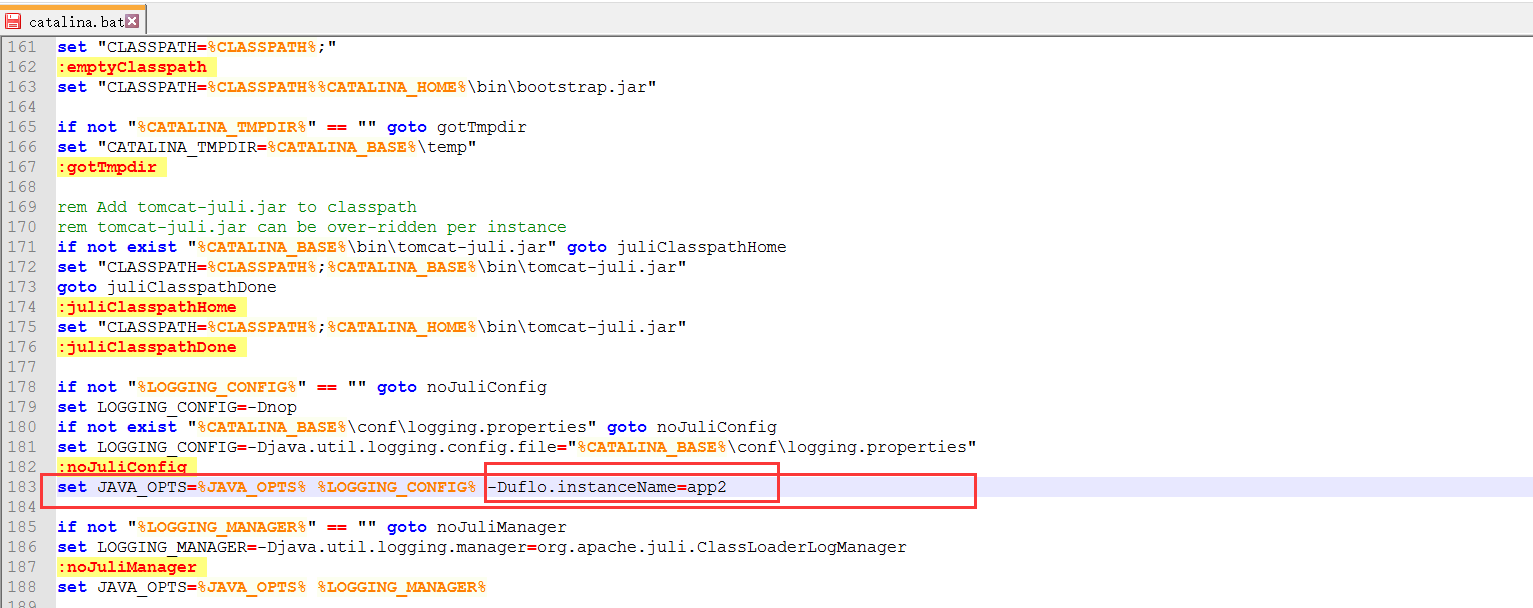
在上图中我们定义了JVM参数“uflo.instanceName”值为“app2”。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}