BaseField
BaseField为Dataset中基本的字段对象。一般对应为数据库表中的一个字段或POJO对象的一个属性。
例如在helloworld例子中,对于datasetEmployee而言,其中的EMPLOYEE_ID、EMPLOYEE_NAME、DEPT_ID等都是普通字段。
如果建立此类型的field,如果可能,建议尽量利用dorado自带的wizard功能:autoCreateField。如下图所示:
1.选择fields
2.点击自动生成字段

图表 15
DummyField
自定义的临时字段,一般只是为了表现层的需要而自定义的字段,这种类型的字段最终不会被更新到数据库或被转换为POJO对象的属性,类似于计算字段。
SelectField
SelectField是一种特殊的字段,通常用以在界面上生成如下的风格:

图表 16
注意看第一列,该处提供一组复选框列表,该字段在dorado开发中用于多选操作处理表格数据行的多选操作。用以同时选中多条记录。Dorado中的数据表格对SelectField有特殊支持,在数据表格中单击SelectField的表头,系统会自动的将所有的复选框选中或取消所有复选框的选中状态。
SelectField与Dataset中其它类型的field不同,该字段的readOnly属性是无效的,也就是说不管Dataset或SelectField的readOnly属性是否为true,SelectField都可以使用。
SelectField的使用方式如下:
Dataset中添加DummyField并设置其name属性为"select";
DataTable中新增column,名称为"select",并设定field属性为"select",绑定到select字段上;
另UpdateCommand的submitScope属性中存在一种"select"的提交类型,这种类型就是指UpdateCommand向Server发出数据提交请求的时候,将DataTable中SelectField处于选中状态的记录提交到Server,详细使用参考<<dorado 5 组件使用详解 v1.1.doc>>UpdateCommand组件说明部分。
LookupField
Dataset LookupField实现代码翻译功能。如下图:

图表 17
如上图中的状态,国别,品种,类型等字段在数据库中存储的都是编码,而在界面显示时,我们通常都需要将编码翻译为名称。
在dorado开发中,如果代码表中的数据量不太大,通常都认为可以用LookupField字段实现。LookupField的实现机制就是利用Dataset在内存中映射一张代码表。并用代码到内存中的映射代码表做匹配,找到匹配的名称取出,从而实现代码翻译功能。该Dataset初始化时会一次性的读取所有的数据,如果设置了pageSize,则读取最前面的pageSize条记录。在执行过程中dataset的内部数据不会再有变动,因此通常情况下代码表中的数据较少时(例如记总数少于500),也就是说即使一次性的读取代码表中的所有数据也不会影响系统的执行效率时我们就可以使用LookupField实现代码翻译功能。
如[图表 18]中国别字段的代码翻译功能可通过如下的方式实现:
- 在Module中定义一个独立的Dataset,读取所有的国别数据;

图表 19
- 对需要实现国别翻译的字段所对应的Dataset中添加LookupField;
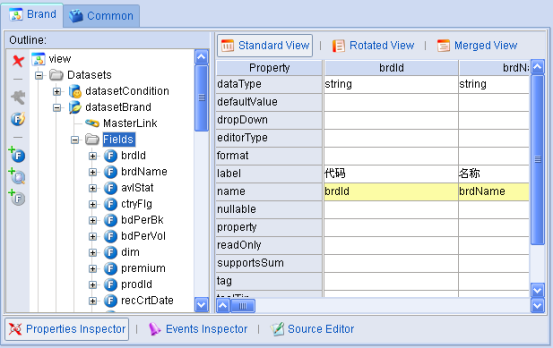
图表 20
- 设定LookupField字段的代码翻译规则:
3.定义翻译规则2.选择翻译字段1.选择数据坞对象 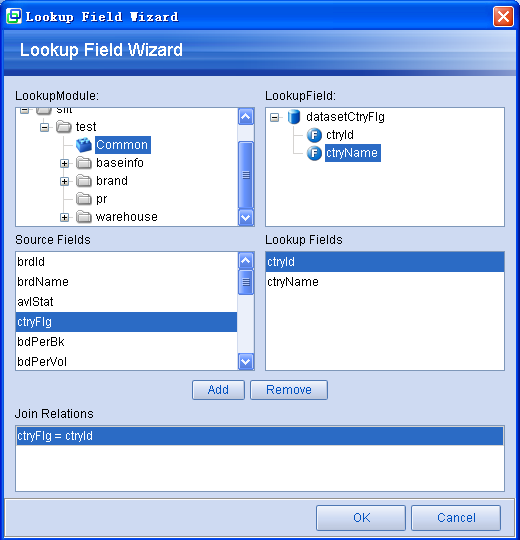
图表 21
在使用Lookup的过程中应该注意下面的一些细节:
- 代码表Dataset(如上例的Common中的datasetCtryFlg)在被用作LookupDataset时不支持分页操作。因为分页很可能会导致部分数据(如上例中datasetBrand中的ctryFlag)无法被Lookup处理机制检索到(如上例中的ctryName)。
- 由此如果分页功能不被支持,那么数据量较大的代码表将是不适用于Lookup的。因为将这么多的数据装载到内存中并建立进行处理将是一笔不可忽视的开销。我们认为一般而言应避免将记录数大于1000的表用作Lookup代码表。同时,应该尽可能缩减Lookup代码表的字段个数,只保留必须的字段。
- 对于代码表Dataset而言,scope属性是相当重要的。因为如果代码表中的数据是相对稳定的,即一般不会被改变的。那么,我们完全可以考虑在它装载数据并建立好内存索引之后,将它暂时缓存起来。这样Dorado可以不必在每次要用到它时都重新执行装载和索引这些过程。这虽会占用一些内存,但对于提高响应速度是有帮助的。
- 将scope设置为application,可以达到将Dataset暂时缓存的目的。另外还有timeout属性可以跟scope配合起来使用,timeout表示当一个被缓存的Dataset在内存中空闲多久以后才可以被自动回收。在home/setting.xml中module.dataset.cache.defaultTimeout这一项表示系统默认的timeout,目前的默认值为12000,即两分钟。如果手工定义了Dataset的timeout属性,那么最终生效的将是手工定义的数值。
- 当一套系统中存在大量的scope为application的Dataset时,可能会占用较多的内存。因此在系统开发的过程中须保持对内存使用量的关注。这里所说的内存占用量与缓存Dataset的个数、Dataset中的数据量、timeout的长短、系统访问频率、访问模式等都是相关的。访问模式需要特别解释一下,如果在一个系统中存在大量的scope为application的Dataset,可是在日常的运行过程中只有小部分是经常被用到的,那么只要timeout配置的得当,就不会有大量的Dataset常驻在内存当中。
- 一般而言,我们不推荐将scope设置为session。这会造成Dorado为每个Session建立一个独立的Dataset缓存,对内存的消耗将更加严重。同时,我们也很少有需要这样来配置。
有关LookupField使用性能问题详情请阅读<<dorado性能指南.Doc>>