情景描述
几乎在所有的企业应用中都会遇到代码翻译的场景,例如将性别代码翻译成男或者女,将民族代码翻译成民族名称,将部门代码翻译成部门名称等。
几种常见的方案
代码翻译的工作是一种对处理数据的需求,而数据在系统中流转通常会有三个驻留地:数据库、服务器、客户端,在这三个地点都有一种典型的处理方案。
方案一:数据库翻译
通过将主表与代码表进行左连接从代码表中获得代码名称字段的内容,这就是数据库端翻译的基本方法。这种方案通常会通过优化SQL语句来提升性能翻译的性能。在Dorado中完全支持这种方案,并且对表间的连接提供了四种连接选项:left_outer_join、right_outer_join、inner_join和select_expression。
方案二:服务器端翻译
有些系统设计者认为通过数据库完成代码翻译的工作会影响数据库性能,将代码表内容放到服务器的缓存中可以提高性能。Dorado也完全支持这种方案,在Dataset中有一种叫做LookupField的字段就是专门用来完成这种工作的,详细信息请参见《dorado 5 用户指南》中的相关篇幅。特别需要指出的是在这种方案中Dorado为缓存提供了一个叫做timeout的属性,用来配置代码表的缓存时间。在规定的时间内如果代码表没有被访问过,那么它在服务器的内存会被释放掉,可以提高服务器的性能。
方案三:客户端翻译
这是需要客户端浏览器进行的工作。将代码表放到客户端的一个Map中,每条记录到Map中进行代码匹配。所以如果代码表或者被翻译的数据量大,通常不建议这种用法。Dorado是通过将ListDropDown或DatasetDropDown的mapValue设置成true完成客户端翻译的,详细信息请参见《dorado 5 用户指南》中的相关篇幅。
一种另类的翻译
这是一种代码翻译的框架,你可以将代码Copy到任何项目中使用。我们先来看一下如何使用这个小框架,然后会展示这段魔术代码。
使用步骤
第一步:定义AutoSqlDataset。
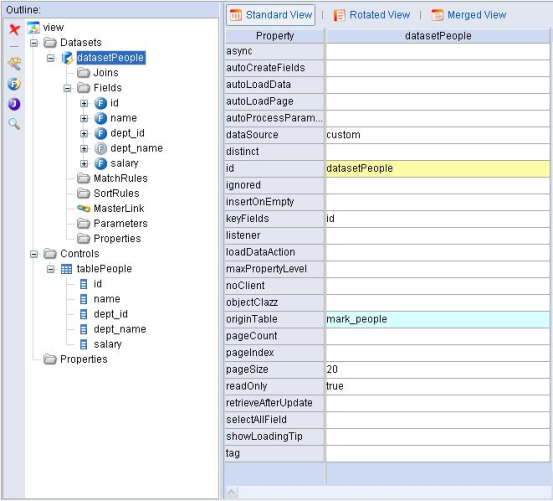
图5.1 定义AutoSqlDataset
datasetPeople与表mark_people关联,没有任何特殊的地方。还定义了一个叫做dapt_name的虚字段。
第二步:定义dept_id字段的properties。
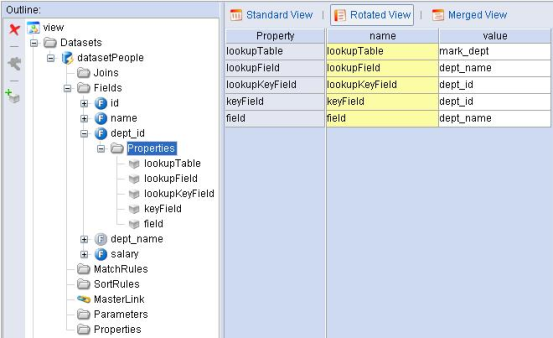
图5.2 定义dept_id字段的properties。
OK,到这里dept_name字段就会根据dept_id中的部门代码变成正确的部门名称了。为了展示被翻译后的数据我们还定了一个叫做tablePeople的DataTable。看一下效果。
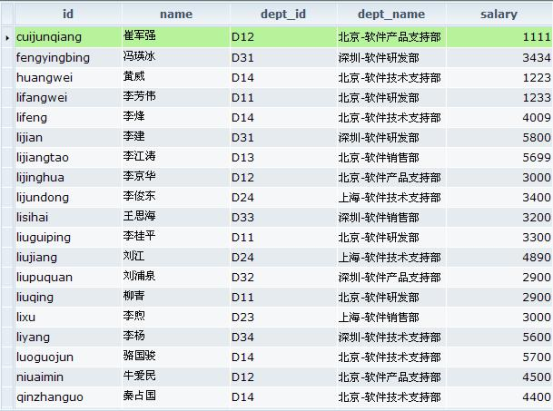
图5.3 被翻译后的数据效果
怎么样,这是不是你见过的最节省程序员体力的代码翻译方案呢?
解决思路
我们在这里使用了DatasetListener,定义为LookupDatasetListener。我们是要做的工作是在LookupDatasetListener的afterLoadData(Dataset dataset)方法中进行翻译。翻译的依据是字段的Properties属性,预定义了以下的property:
- keyField:被翻译的代码字段。
- field:存放翻译结果的字段。
- lookupTable:代码表名。
- lookupKeyField:代码表的代码字段。
- lookupField:代码表的名称字段。
- cache:缓存模式。
根据这些properties的配置信息可以生成代码翻译的SQL语句,将查询结果赋值到配置的字段中。
源代码
LookupViewModel的源代码:
package com.bstek.mark.view.custom.lookup;
import com.bstek.dorado.data.DatasetListener;
import com.bstek.dorado.view.DefaultViewModel;
import com.bstek.dorado.view.data.ViewDataset;
public class LookupViewModel extends DefaultViewModel {
private static final DatasetListener lookupDatasetListener = new LookupDatasetListener();
@Override
protected void initDataset(ViewDataset dataset) throws Exception {
super.initDataset(dataset);
dataset.addDatasetListener(lookupDatasetListener);
}
} |
值得注意的地方是DatasetListener是通过代码添加的,不需要手动配置。这样做的意义在于任何继承LookupViewModel的视图模型类都可以使用这种Lookup功能。
LookupDatasetListener的源代码:
package com.bstek.mark.view.custom.lookup;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.TreeSet;
import org.apache.commons.lang.StringUtils;
import com.bstek.dorado.common.DoradoContext;
import com.bstek.dorado.common.Transaction;
import com.bstek.dorado.common.TransactionManager;
import com.bstek.dorado.data.AbstractDatasetListener;
import com.bstek.dorado.data.Dataset;
import com.bstek.dorado.data.Field;
import com.bstek.dorado.data.Record;
import com.bstek.dorado.data.RecordIterator;
import com.bstek.dorado.utils.MetaData;
public class LookupDatasetListener extends AbstractDatasetListener {
private static final String MAP_POOL = "MAP_POOL";
private static final String ATTRIBUTE_CACHE_POOL = LookupDatasetListener.class
.getName()
+ ".lookupCachePool";
@SuppressWarnings("unchecked")
@Override
public void afterLoadData(Dataset dataset) throws Exception {
super.afterLoadData(dataset);
Set<LookupDescriptor> lookupSet = new TreeSet<LookupDescriptor>(
new Comparator<LookupDescriptor>() {
public int compare(LookupDescriptor lookupDescriptor1,
LookupDescriptor lookupDescriptor2) {
int code = lookupDescriptor1.getSql().compareTo(
lookupDescriptor2.getSql());
if (code == 0 && lookupDescriptor1 != lookupDescriptor2) {
code = 1;
}
return code;
}
});
int fieldCount = dataset.getFieldCount();
for (int i = 0; i < fieldCount; i++) {
Field field = dataset.getField ; ;
MetaData properties = field.properties();
String lookupTable = properties.getString("lookupTable");
if (StringUtils.isNotEmpty(lookupTable)) {
String keyFieldName = properties.getString("keyField");
if (StringUtils.isEmpty(keyFieldName)) {
keyFieldName = field.getName();
}
String lookupField = properties.getString("lookupField");
String lookupKeyField = properties.getString("lookupKeyField");
String fieldName = properties.getString("field");
String cacheMode = properties.getString("cache");
cacheMode = StringUtils.defaultIfEmpty(cacheMode, MAP_POOL);
FieldsDescriptor fieldsDescriptor = new FieldsDescriptor(
keyFieldName, lookupField, lookupKeyField, fieldName);
String sql = getLookupSQL(lookupTable, fieldsDescriptor);
LookupDescriptor lookupDescriptor = new LookupDescriptor(
fieldsDescriptor, sql, cacheMode);
lookupSet.add(lookupDescriptor);
}
}
if (lookupSet.size() > 0) {
Transaction transaction = TransactionManager.getTransaction();
Connection connection = transaction.getConnection(null);
PreparedStatement lookupStatement = null;
String LastLookupSql = null;
try {
for (Iterator<LookupDescriptor> iter = lookupSet.iterator(); iter
.hasNext() { {
LookupDescriptor lookupDescriptor = iter.next();
FieldsDescriptor fieldsDescriptor = lookupDescriptor
.getFieldsDescriptor();
String sql = lookupDescriptor.getSql();
String cacheMode = lookupDescriptor.getCacheMode();
Map lookupResultPool = null;
if (!sql.equals(LastLookupSql)) {
if (lookupStatement != null) {
lookupStatement.close();
}
lookupStatement = connection.prepareStatement(sql);
if (MAP_POOL.equals(cacheMode)) {
lookupResultPool = getLookupResultPool(sql);
}
}
processLookup(lookupStatement, lookupResultPool, dataset,
fieldsDescriptor);
}
} finally {
try {
if (lookupStatement != null) {
lookupStatement.close();
}
} finally {
connection.close();
}
}
}
}
@SuppressWarnings("unchecked")
private Map getLookupResultPool(String sql) {
DoradoContext context = DoradoContext.getContext();
Map poolMap = (Map) context.getAttribute(DoradoContext.REQUEST,
ATTRIBUTE_CACHE_POOL);
if (poolMap == null) {
poolMap = new HashMap();
context.setAttribute(DoradoContext.REQUEST, ATTRIBUTE_CACHE_POOL,
poolMap);
}
Map pool = null;
if (poolMap != null) {
pool = (Map) poolMap.get(sql);
if (pool == null) {
pool = new HashMap();
poolMap.put(sql, pool);
}
}
return pool;
}
@SuppressWarnings("unchecked")
protected void processLookup(PreparedStatement lookupStatement,
Map lookupCachePool, Dataset dataset,
FieldsDescriptor fieldsDescriptor) throws Exception {
String[] fields = fieldsDescriptor.getFields();
String[] keyFields = fieldsDescriptor.getKeyFields();
for (int i = 0; i < fields.length; i++) {
String fieldName = fields[i];
Field field = dataset.getField(fieldName);
if (field == null) {
dataset.addDummyField(fieldName);
}
}
RecordIterator ri = dataset.recordIterator();
while (ri.hasNext()) {
Record record = ri.nextRecord();
// 此判断纯粹用于提高效率,绝大部分情况下length == 1
if (keyFields.length == 1) {
String keyValue = record.getString(keyFields[0]);
if (keyValue == null) {
continue;
}
String result = null;
if (lookupCachePool != null
&& lookupCachePool.containsKey(keyValue)) {
result = (String) lookupCachePool.get(keyValue);
} else {
lookupStatement.setString(1, keyValue);
ResultSet rs = lookupStatement.executeQuery();
try {
if (rs.next()) {
result = rs.getString(1);
if (lookupCachePool != null) {
lookupCachePool.put(keyValue, result);
}
}
} finally {
rs.close();
}
}
if (result != null) {
record.setString(fields[0], result);
}
} else {
boolean shouldSkip = true;
String[] keyValues = new String[keyFields.length];
for (int i = 0; i < keyFields.length; i++) {
// 暂时全部按照String来处理
String keyField = keyFields[i];
String keyValue = record.getString(keyField);
if (keyValue != null) {
keyValues[i] = keyValue;
shouldSkip = false;
}
}
if (shouldSkip) {
continue;
}
String[] results = null;
if (lookupCachePool != null) {
results = (String[]) lookupCachePool.get(keyValues);
}
if (results == null) {
for (int i = 0; i < keyValues.length; i++) {
lookupStatement.setString(i + 1, keyValues[i]);
}
ResultSet rs = lookupStatement.executeQuery();
try {
if (rs.next()) {
results = new String[fields.length];
for (int i = 0; i < fields.length; i++) {
// 暂时全部按照String来处理
results[i] = rs.getString(i + 1);
}
if (lookupCachePool != null) {
lookupCachePool.put(keyValues, results);
}
}
} finally {
rs.close();
lookupStatement.clearParameters();
}
}
if (results != null) {
for (int i = 0; i < fields.length; i++) {
// 暂时全部按照String来处理
record.setString(fields[i], results[i]);
}
}
}
}
}
protected String getLookupSQL(String lookupTable,
FieldsDescriptor fieldsDescriptor) {
String[] lookupFields = fieldsDescriptor.getLookupFields();
String[] lookupKeyFields = fieldsDescriptor.getLookupKeyFields();
StringBuffer sql = new StringBuffer();
sql.append("SELECT ");
for (int i = 0; i < lookupFields.length; i++) {
sql.append((i > 0) ? ", " : "").append(lookupFields[i]);
}
sql.append(" FROM ").append(lookupTable).append(" WHERE ");
for (int i = 0; i < lookupKeyFields.length; i++) {
if (i > 0) {
sql.append(" AND ");
}
sql.append(lookupKeyFields[i]).append("=?");
}
return sql.toString();
}
class FieldsDescriptor {
private String[] fields;
private String[] keyFields;
private String[] lookupFields;
private String[] lookupKeyFields;
public FieldsDescriptor(String keyField, String lookupField,
String lookupKeyField, String field) {
final String SEPERATORS = ",";
//Assert.hasLength(keyField);
//Assert.hasLength(lookupField);
keyFields = keyField.split(SEPERATORS);
lookupFields = lookupField.split(SEPERATORS);
if (StringUtils.isEmpty(lookupKeyField)) {
lookupKeyFields = keyFields;
} else {
lookupKeyFields = lookupKeyField.split(SEPERATORS);
}
if (StringUtils.isEmpty(field)) {
fields = lookupFields;
} else {
fields = field.split(SEPERATORS);
}
}
public String[] getFields() {
return fields;
}
public String[] getKeyFields() {
return keyFields;
}
public String[] getLookupFields() {
return lookupFields;
}
public String[] getLookupKeyFields() {
return lookupKeyFields;
}
}
class LookupDescriptor {
private String sql;
private FieldsDescriptor fieldsDescriptor;
private String cacheMode;
public LookupDescriptor(FieldsDescriptor fieldsDescriptor, String sql,
String cacheMode) {
this.sql = sql;
this.fieldsDescriptor = fieldsDescriptor;
this.cacheMode = cacheMode;
}
public String getCacheMode() {
return cacheMode;
}
public FieldsDescriptor getFieldsDescriptor() {
return fieldsDescriptor;
}
public String getSql() {
return sql;
}
}
}
|
上面的代码需要注意的地方是:内将翻译的结果在Request范围内做了缓存,也就是说在遇到相同的代码翻译语句时不会查询数据库,而是在缓存中查找,减少数据库访问次数。
(完)
文档信息
文档中文名称 |
灵活使用dorado5 |
|
|
文档英文名称 |
Dorado 5 Smart Development |
|
|
文档内容简介 |
《灵活使用dorado 5》是面向具有dorado中级开发能力的群体,向大家展示如何灵活运用Dorado模型以及按照Dorado的思维来解决非典型的应用需求,文档重点以思路分析与代码展示为主,讲述了一种叫做VBC的面向业务的客户端代码的编写风格,帮助我们保持业务流程和脚本结构的清晰度。 |
|
|
文档分享范围 |
公开文档 |
|
|
日期 |
作者 |
版本 |
变更说明 |
2007年09月07日 |
Mark.li@bstek.com |
V1.0 |
创建 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|