要进行下一步部分之前,需要先来了解一下在客户端的操作当中,哪一些操作是较昂贵的。这类操作主要包括一下这两类:
- 远程过程调用操作。包括同步模式的Dataset的flushData()、UpdateCommand、RPCCommand等。操作是否同步模式是由Dataset、UpdateCommand和RPCCommand的async属性决定的。async为false代表同步模式,该属性的默认值为false。
- 会引起数据敏感控件刷新的操作。通常,改变Dataset中的数据,移动当前记录等操作都会引起相关数据敏感控件的更新动作。
事实上,下面所介绍的很多技巧的目的都是为了尽可能的减少或者掩盖以上这两种操作。
利用布局技巧改善操作体验
在2.3节中曾经提到,Dorado中的TabSet、GroupBox、SubWindow、OutlookBar这几个控件是带有"懒装载"功能的。此处的"懒装载"是指这些控件都可以在页面展开的过程中,暂时忽略那些用户当前看不到的控件。直到用户进行了某些操作而需要显示它们时,才逐步的把它们创建出来。使用这种技巧,常常可以使你的页面的开发速度获得几倍的提高。
对于TabSet和OutlookBar而言,在页面刚打开时,Dorado只会初始化其中一个标签页或组中的控件,直到用户要切换到另一个标签页或组时Dorado才会创建和初始化那个标签页或组的控件。
对于SubWindow和GroupBox而言,如果他们正处于最小化状态或收缩状态,那么在页面打开时,Dorado并不会初始化其中的控件。直到用户还原SubWindow或者展开GroupBox时,其内部的控件才会被创建出来。
对于控件数量较多的页面,我们可以利用这个特性对其初始的打开速度进行优化。例如将控件分散到TabSet的各个标签页中;或者使用多个GroupBox来的包裹这些组件,并且将不是最关键的那些GroupBox设置为收缩状态。
如果使用Dorado中的AutoForm来构建表单,只要为这些编辑框进行分组AutoForm就会将它们包裹到多个GroupBox中,且除第一个组之外,其它各组默认都是收缩状态的。
哪些逻辑代码应该放在onDatasetsPrepared事件中
通常,开发人员都会把需要在页面打开时自动执行的代码写在ViewModel的onLoad事件中。不过,如果把那些初始化Dataset数据的代码放在onDatasetsPrepared事件中将会获得更高的效率。
先来了解一下Dorado页面的初始化过程。
- 页面下载完成。
- 创建所有的Dataset。
- 触发onDatasetsPrepared事件。
- 创建所有非可视化控件(DropDown、Menu、Command)。
- 创建必须的可视化控件。建立其中的数据控件与Dataset的绑定关系。
- 所有的Dataset向绑定的数据敏感控件发出数据刷新的消息,数据敏感控件显示出数据。
- 触发onLoad事件。
从上面的过程可见,当执行到第6个步骤时数据敏感控件事实上已经就绪。如果您在onLoad事件中对Dataset总的数据做了修改,那么Dataset将不得不重新向绑定的数据敏感控件发送数据被更新的消息,导致数据敏感控件发生更新动作。而如果这些代码是写在onDatasetsPrepared事件中的,那么你对数据的修改将在第6个步骤中被一并处理,每一个敏感控件只需要刷新一次数据。
当我们需要编写在页面加载时自动执行的代码时,应该首先考虑使用onDatasetsPrepared事件。但是,onDatasetsPrepared事件并不能完全替代onLoad事件,主要原因是在系统触发onDatasetsPrepared事件时ViewModel中的控件还没有被创建出来,如果您的逻辑代码中包含控件的直接操作,那么这一部分代码将只能写在onLoad事件中。有时,我们需要同时使用这两个事件,在onDatasetsPrepared事件中初始化Dataset,在onLoad事件中处理控件。
如何遍历Dataset
遍历一个Dataset中的数据主要有以下两种方式:
- 方法一
datasetX.moveFirst();
while (!datasetX.isLast()) {
... ... ...
datasetX.moveNext();
} - 方法二
如无特殊需要,我们推荐使用第二种方法完成对Dataset的遍历。这两种遍历方式的区别在于,第一种遍历方式是通过不断的改变Dataset的当前记录来完成遍历操作的,而第二种遍历方式在遍历的过程中并不会改变Dataset的当前记录。如果此时有任何数据敏感控件绑定在Dataset上,那么,改变Dataset的当前记录将会引起数据敏感控件的刷新动作。如果Dataset中有n条记录,在默认情况下,以第一种方式进行遍历将至少引起相关的数据敏感控件刷新n次,并且当遍历操作结束之后Dataset的当前记录应该总是最后一条记录。
var record = datasetX.getFirstRecord();
while (record != null) {
... ... ...
record = record.getNextRecord();
}
另外,如果被遍历的Dataset是主从绑定关系中的主Dataset。那么直接使用第一种遍历方式将会更加危险,其下的从Dataset可能会随着主Dataset当前记录的改变不断的执行数据加载的动作。数据加载是一种比控件刷新更加耗时的操作。
很多时候,我们使用Dataset遍历是为了修改其中的每一条记录。在这种情况下,如果仅仅是使用此处第二种遍历方式,还远没有达到效率最佳化的目标。此时一定要结合3.4.4中介绍的disableControls()和enableControls()才能得到更好的运行效果。
实测数据:
以两种方式对一个包含2000条记录的Dataset进行遍历。实测环境的CPU为INTER Pentium(R) 1.73G。 - 方法一的耗时为0.256秒。(在进行此方法的测试时我们使用了3.4.4中介绍的disableControls()和enableControls()关闭了数据控件的刷新功能,否则速度将慢得无法忍受)
- 方法二的耗时为0.047秒。
由此可见,两种方式间有接近一个数量级的性能差异。方法二的优势非常明显。
disableControls()和enableControls()
Dataset的disableControls()方法和enableControls()方法大概是Dorado开发中最常用的优化技巧了。这个方法非常容易使用,而获取的效果也非常显著,他常常可以将一段代码的执行速度提高好几倍甚至更多。
disableControls()表示暂时禁用Dataset的绑定关系,即暂时禁止Dataset向绑定的数据敏感控件发送任何消息,这样数据敏感控件就不会随着Dataset的变化而自动刷新的。enableControls()则正好相反,表示重新允许Dataset向绑定的数据敏感控件发送消息。
disableControls()和enableControls()往往会跟Dataset.refreshControls()方法一起配置使用。refreshControls()的作用是通知所有与改Dataset绑定的数据敏感控件立即进行数据刷新。
假设我们现在要编写一段代码将Dataset中每一条记录的status字段的值设置为completed。未经优化的代码可能是这样的:
var record = datasetX.getFirstRecord(); |
假设DatasetX中有n条记录,那么,进行一次这样的遍历将导致相关的数据敏感控件被刷新n次。其实这n次刷新中的前n-1次都是没有任何意义的。
利用disableControls()、enableControls()结合refreshControls()优化之后的代码可能是这样的:
datasetX.disableControls(); |
这样在执行循环的过程中数据敏感控件完全不会刷新,直到循环结束之后,手工调用refreshControls()通知数据敏感控件进行数据刷新。整个操作将需要进行这一次刷新。
disableControls()、enableControls()并不总是用在循环操作中,只要是针对Dataset的批量操作都考虑使用这种优化技巧。例如下面的这段用于数据复制的未优化代码:
dataset1.setValue("id", "0001"); |
我们同样可以使用disableControls()和enableControls()对其进行优化,优化后的代码可能如下:
datasetX.disableControls(); |
使用disableControls()和enableControls()时还应该注意这样一个细节,这两个方法的运行机制类似于计数器,而不是通常理解的开关。如果对一个Dataset连续执行两次disableControls()方法,那么也必须再执行两次enableControls()才能重新启用绑定关系,即回复Dataset向数据敏感控件发送消息。
下面的代码可能有助于您理解disableControls()和enableControls()的运行机制:
// 此时绑定可用 |
实测数据:
对一个包含50条记录的Dataset进行遍历,并在遍历的过程中修改每一条记录中的5个字段值。
实测环境的CPU为INTER Pentium(R) 1.73G。需要注意的是,此处的测试结果与界面的复杂度密切相关,测试的主要目的是确认未优化代码与优化代码间的性能差异。越是复杂的界面其差异越明显,所以具体的时间值本身参考价值并不大。
- 未经优化的测试代码,其耗时为2.016秒。
var record=dataset1.getFirstRecord();
while (record!=null) {
record.setValue("field1", "123");
record.setValue("field2", "234");
record.setValue("field3", "345");
record.setValue("field4", "456");
record.setValue("field5", "567");
record.post();
record=record.getNextRecord();
} - 优化后的测试代码,其耗时为0.25秒。
dataset1.disableControls();
try {
var record=dataset1.getFirstRecord();
while (record!=null) {
record.setValue("field1", "123");
record.setValue("field2", "234");
record.setValue("field3", "345");
record.setValue("field4", "456");
record.setValue("field5", "567");
record.post();
record=record.getNextRecord();
}
}
finally {
dataset1.enableControls();
dataset1.refreshControls();
}disableEvent()和enableEvent()
Dataset的disableEvent()方法的作用是暂时禁用Dataset的所有事件,即阻止Dataset的中的事件被触发。与之相反,enableEvent()的作用是重新启用Dataset的事件机制。
disableEvent()和enableEvent()的使用方式与前面在3.4.4节中介绍过的disableControls()和enableControls()的使用方式相似,并且他们的运行机制也很类似,disableEvent()和enableEvent()同样是以计数器的方式运行的。
disableEvent()和enableEvent()只有在一部分比较特殊的情况下才能起到提高运行效率的作用,这取决于开发人员对Dataset事件的使用方式。下面我们来分析一个实例。
设想一个合同信息维护的界面,界面中有一个合同明细的列表。一般而言,每一项合同明细对应一种商品。我们需要在界面上实现这样一个功能,每当用户在列表中选择一个商品时,我们就在页面的另一个区域中显示出这种商品的历史成交信息。出于某种原因,这里没有在明细信息Dataset和历史成交信息Dataset之间建立主从连接,而是利用明细信息Dataset的afterScroll事件,在其中调用历史成交信息Dataset的flushData(),以便于从服务端动态的得到相关的历史成交数据。而界面上还有一个"批量添加产品"的按钮,用户可以通过在一个弹出式"产品选择"的窗体中批量选择,一次性的向合同明细中添加一组产品。
在通过"产品选择"窗体进行批量添加产品时,我们应该一定会使用Dataset的insertRecord()方法,insertRecord()方法会改变Dataset的当前记录。这样,问题就来了。批量添加产品的操作过程中会多次使用insertRecord(),即会多次触发Dataset的afterScroll事件,有多少记录被添加就会有多少次提取历史成交信息的操作。而事实上,只有最后一次提取信息的操作是有效的。
要改善这里的执行效率,我们可以考虑这样来编写批量添加产品的代码:往往,使用disableEvent()和enableEvent()并不是解决这一类问题的最好解决办法。因为disableEvent()会很彻底的禁用掉Dataset中定义的所有的事件,如果我们还在datasetContractItem的afterInsert事件中添加了一些初始化明细记录的逻辑代码的话,那么它也会被一同禁用掉,这应该是不合需要的。datasetContractItem.disableControls();
datasetContractItem.disableEvent();
try {
... ... ...
(批量添加产品的代码)
... ... ...
}
finally {
datasetContractItem.enableEvent();
datasetContractItem.enableControls();
datasetContractItem.refreshControls();
... ... ...
(手工提取产品的历史成交记录的代码)
... ... ...
}
所以,在实际应用的过程中,我们可能常常需要利用全局状态变量的方式来替代这种做法。具体的做法可能如下:
在ViewModel的<functions>中添加一个全局变量:在datasetContractItem的afterScroll事件中添加对disableRetrievingHistroy的判断:var disableRetrievingHistroy = false;
同时,按照这样的方式来编写批量添加产品的代码:if (disableRetrievingHistroy) return;
... ... ...
(提取产品的历史成交记录的代码)
... ... ...datasetContractItem.disableControls();
disableRetrievingHistroy = true;
try {
... ... ...
(批量添加产品的代码)
... ... ...
}
finally {
disableRetrievingHistroy = false;
datasetContractItem.enableControls();
datasetContractItem.refreshControls();
... ... ...
(手工提取产品的历史成交记录的代码)
... ... ...
}警惕主从绑定带来的连锁反应
主从绑定(MasterLink)的概念来自于Delphi,是一种方便易用的建立Dataset间从属关系的方法。主从绑定的运行机制具有很强的自主性,它可以帮助我们在不编写任何一行代码的情况创建出具有较复杂数据关系的界面。不过,也正因为有了这种自主性,我们必须在使用前对它有一定的了解。否则,很可能因为对它的不恰当使用而导致界面的性能问题。
主从绑定一旦建立之后,从Dataset就可以可以被视作是一个绑定在主Dataset上的数据敏感控件,它会监听来自主Dataset的各种消息。不过它只关心"当前记录改变"这一种消息。我们可以设想从Dataset是以多个分组来管理其中的数据(似乎有点类似TabSet,不过它们是不可见的),任何时刻都只会有一个分组是有效的,该分组与主Dataset的当前记录相匹配。当从Dataset得到来自主Dataset的"当前记录改变"消息时,他会立刻尝试将将与主Dataset的当前记录相匹配的那个组切换为当前组。如果此时改组中的数据尚未加载过,那么主Dataset会自动调用一个远程的数据加载动作,从服务端得到需要的数据。这个远程的数据加载动作类似于我们常用的Dataset的flushData()操作。也就是说我们对主表所做的任何操作,只要改变了当前记录,就有可能会引发从Dataset执行一个相对耗时的远程的数据加载动作。而且该操作总是同步模式的,它在执行时会引起界面上其他的一切功能被暂时阻塞。
从Dataset的远程的数据加载动作往往都是在无声无息中完成的。所以,很不幸,那些经验不足的开发人员常常会忽视它的存在。主从绑定在页面上并不总是简单的"1对1"关系,我们经常需要建立复杂的"1对n对n"的主从绑定。如果在这种界面上仍不重视这种远程的数据加载的存在,那就很可能会导致严重的问题。
设想下面的这个例子:
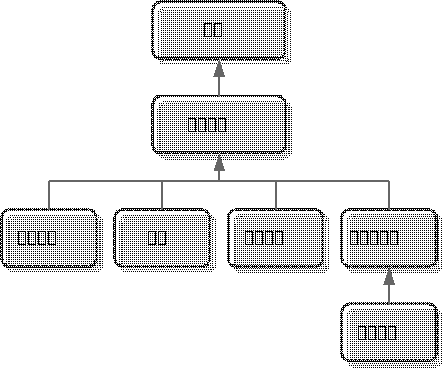
在系统的某一个用于显示一个部门中所有员工的界面中实现了这样的七个Dataset,形成了一种较复杂的主从绑定关系。其中,这里的员工信息是显示在一个列表当中的。这个界面的设计是很为用户着想的,他可以在一个界面中方便的浏览一个部门中所有员工的详细信息。
可是,如果直接将一个这样设计的页面交付给用户很可能相反的反馈。用户总是抱怨,每当他点击列表试图切换到某个员工时页面总是会有一段令人不悦的停顿。要分析这里的原因其实并不难。每当用户切换当前员工时,都会引起"联系方式"、"亲属"、"教育经历"、"曾任职公司"这4个子Dataset执行远程数据加载动作。同时"曾任职公司"的数据加载完成之后,由于记录被改变了,又会进一步引起"工作业绩"的数据加载工作。可见,切换一下当前员工会引起总共5个远程的数据加载操作,界面产生停顿也就不难理解了。
在这种情况下可以考虑一下三种方式之一来改进页面。 - 方法一:实现从数据的懒装载。
这种具有复杂数据关系的页面一般都会采用TabSet来辅助界面布局,因为如此丰富的界面元素不大可能一下子堆放在同一个视图区中。对上面的例子而言,其界面很可能是这样来设计的。

这种界面有一个特点,那就是所有的界面元素不可能在同一时刻显示出来,用户多能看到和操作的只是其中的一小部分。这样一来我们就有了优化的空间。因为当用户停留在"员工列表"界面时,我们并需要去提取其他4个标签页中的数据,我们只需要在用户将换面切换到某一个标签页中之后,才需要提取与该标签页相关的那一部分从数据。
按照这种思路,我们可以这样来改进页面。首先删除主从绑定,然后在TabSet的afterTabChange事件中编写代码。根据当前激活的标签页执行相应从Dataset的数据加载操作。例如:
var subDataset = null; |
- 方法二:暂时禁用主从绑定。
上面的方法虽然极简单有高效,但是并不能在所有情况下适用。有时,我们必须保留Dataset间的主从绑定关系。这是因为主从绑定并不仅仅是帮我们实现显示方面的功能,也可以在数据提交保存时发挥作用(这主要是指利用Dorado的SqlDataset或AutoSqlDataset的情况)。它可以实现为从Dataset自动设定外键值的功能。如果您希望保留主从绑定的这一功能,同时又要提高界面的响应速度。那就应该考虑使用此处的方法。
在前面的篇幅中我们曾经提到过,我们可以把从Dataset看作是绑定在主Dataset上的数据敏感控件,从Dataset是根据从Dataset获得消息来决定自己何时应该执行数据加载的。如果我们能够保留主从绑定关系,但在必要的时候阻止从Dataset得到来自主Dataset的消息,那就一样可以起到优化的目的。
要实现上述功能,需要使用从Dataset的disableBinding()和enableBinding()这两个方法。这两个方法表示暂时禁用和启用绑定关系。一旦绑定关系被禁用,从Dataset(或者说是数据敏感控件)就将无法得到来自Dataset的消息。
具体的做法是这样,在ViewModel的onDatasetsPrepared事件中添加下列代码:
datasetContract.disableBinding(); |
这样,在界面一打开时我们就禁用了这4个从Dataset与主Dataset间的绑定关系,用户对主Dataset的操作将不会引起从Dataset的任何动作。同时我们需要保证用户在切花TabSet时能够看到正确的数据,因为我们仍需要定义TabSet的afterTabChange事件:
var subDataset = null; |
这里的refresh()方式是所有数据敏感控件的都具有的一个方法,从Dataset当然也不例外。它的执行效果等同于接收到一个来自主Dataset的"全部刷新消息"。我们在此处调用refresh()相当与模拟了一来自主Dataset的消息,从而确保从Dataset的数据与主Dataset的数据同步。
我们不需要在页面unload时或者提交之前调用enableBinding()来重新启用主从绑定关系。因为在客户端的禁用主从绑定关系并不会影响服务端的处理逻辑。
此方法实现的页面与第一种方法实现的页面只有一点区别,那就是"联系方式"、"亲属"、"教育经历"、"曾任职公司"这4个子Dataset会在页面打开时直接加载好跟第一位员工相匹配的子记录,这些记录可以通过查看浏览器中的"源文件"找到。其实,对于实现了此类优化的页面而言,这第一次的数据自动装载是完全没有必要的,尽管他对性能的影响不大。要阻止子Dataset的第一查询并不困难,只要在ViewModel中将这4个子Dataset的loadData属性设为false就可以了。
- 方法三:使用异步数据装载。
这种方法是指删除原有的主从绑定关系,同时使用异步模式来为从Dataset装载数据。该方法对于优化主从绑定而言,与前两种方法相比并没有什么优势,不过它是一种适用面非常广的优化技巧,也体现了AJAX的精髓。具体的操作方法请参考3.4.13 — 使用异步操作。
利用dataset的autoLoadPage属性改善操作体验
dataset的autoLoadPage属性需要跟Dorado的DataTable结合起来使用才能发挥他的作用。它可以帮助我们在尽可能少损失性能的前提下实现对大数量的不分页浏览。
尽管在Web应用中使用分页来展示较大行数的内容早已成为了一种标准的做法。但是对于那些已经用惯了CS应用的用户仍有可能百般要求不要对数据进行分页处理。不管怎样,不对较大的结果集分页都是不可取的。要是真的一次性的把几千、几万条记录加载到客户端,就算浏览器吃的消网络传输也会暂用很长的时间,而且当数据进一步加大时引起服务器宕机也说不定。
不过,利用Dorado我们可以分页处理的表象隐藏起来,使它看起来好像没做过分页。演示这一功能的例子可以在下面的网址看到。
http://61.151.239.187/dorado5/new-feature/new-table.jsp?autoLoadPage=true&pageSize=5

autoLoadPage的运行机制仍然是依赖于分页查询的。在页面打开时该机制只会向的客户端传送第一页的数据,其它页的加载过程被隐藏到了DataTable的操作过程中。例如当用户拖动纵向滚动条时、或者用户点击某条尚未下载的页中的记录时,DataTable会自动利用绑定的Dataset完成数据加载的功能。
在上图的例子中为了清晰的演示数据被分批加载的过程,特意将每页的记录数(即Dataset的pageSize属性)设定为了5。当实际应用的过程,我们应该将每页的记录数设定为一个更大的数字。例如:当数据DataTable一次可以显示20条记录时(此记录数与DataTable的高度和数据行的高度设定有关),那么我们可以考虑将每页的记录数设定为30或50。这样在用户进行常规操作时是不会看到上图中那些灰色的未下载记录的。
为部分下拉框热身
Dorado中目前有5种标准的下拉框类型:ListDropDown、DateDropDown、DatasetDropDown、DynamicDropDown、CustomDropDown。
其中DynamicDropDown和CustomDropDown这两种是利用HTML中的IFrame元素实现的。也就是说他们的本质是一个独立的页面,Dorado将它显示在下拉框的IFrame中,并且赋予了它向主页面返回信息的功能。使用这两种下拉框可以有效的减小主页面的尺寸和负载,因为下拉框中的数据并不会随着主页面的打开而被一并下载。在一个页面中大量使用DynamicDropDown和CustomDropDown并不会明显的增加主页面加载过程的负担。不过,这样的机制也会带来一些问题。DynamicDropDown和CustomDropDown第一次打开的速度会明显慢于其它三种下拉框,因为打开下拉框的过程相当请求一个独立的JSP页面。
为了解决这一问题,Dorado中特别为DynamicDropDown和CustomDropDown提供了一个warmUpDelay属性。warmUpDelay是一个数字型的属性,表示自动预热的延时时间。预热的内部操作过程就是利用一个隐含的IFrame,预先访问一下下拉框中的页面并将该IFrame缓存起来,以起到加快相应的下拉框第一次使用是的速度的目的。不设置此属性或设置为0,表示不启用此功能。warmUpDelay单位是0.1秒。例如:20表示2秒,设置了此属性就可以在页面打开之后2秒钟左右在浏览器的状态栏中看到类似下图的字样闪现,这代表某下拉框正在预热。
![]()
使用warmUpDelay属性时需要注意一个问题,warmUpDelay属性不能用在不支持缓存的下拉框上,即不能用在cachable属性为false的下拉框上。如果在cachable属性为false的下拉框上设置了warmUpDelay属性,那么该属性是不会生效的。
在对一个页面上的多个下拉框设置warmUpDelay属性时,应注意尽量使用不同的warmUpDelay数值,以避免在同一时刻发起大量请求造成服务器的负担过重,最好能够将时间错开,例如每隔0.5秒激活一个到两个下拉框。
另外还应该注意一点,不要不假思索的把页面中所有的DynamicDropDown和CustomDropDown类型的下拉框设为自动预热。最好只把页面上那些常被用到的下拉框设为自动预热,这样可以避免一些无谓的资源浪费。
谨慎使用下拉框的mapValue特性
Dorado中的ListDropDown和DatasetDropDown这两个下拉框都支持自动将代码翻译为名称的功能,即通过将其mapValue属性设为true时打开的功能。这是非常容易使用的功能,不过如果毫无节制的使用此功能将有可能影响页面性能。
首先,我们需要了解一下mapValue的内部运行机制。mapValue有点类似于在客户端执行的Lookup。mapValue使用的所有键值对事实上都是保存在一个Dataset中的,对于DatasetDropDown而言这个Dataset就是他绑定的Dataset,对ListDropDown而言,该Dataset是一个由ListDropDown自动创建的匿名Dataset(ListDropDown内部的匿名Dataset,可以通过ListDropDown的getDataset()方法获得)。在页面打开后第一次使用时,下拉框将这个Dataset中所有的键值对取出并保存到一个类似HashMap的数据结构当中。在之后的"代码翻译"过程中,下拉框将直接利用代码到此"HashMap"中获得相应的名称。
上面的过程反映了两个要点:
- 所有的翻译操作都是在客户端利用JavaScript完成的。
- 所有的代码数据都必须一次性的被下载到客户端,以便在进行第一次翻译之前Dorado为他们建立索引。
掌握了这些之后,我们就需要在使用这两种下拉框的MapValue功能时注意下面一些事项:
- ListDropDown中的下拉项目不宜过多,最好控制在100条以内。
- DatasetDropDown如果绑定的Dataset中的数据应该是一次性下载的, AutoLoadPage和pageSize等属性都不能很好的与MapValue功能兼容,因为下拉框不会实时的根据新加载的数据去更新索引信息。
- 同样,DatasetDropDown如果绑定的Dataset中的数据也不宜过多,最好控制在100条以内。
- 以上数据并不是绝对的,跟实际的使用方法、客户的操作反馈有关。比如当一个界面上只有一、两个支持mapValue的下拉框,或者页面上使用表单展示数据时,就可以适当的突破100条下拉记录的上限。可是如果页面上有很多这样的下拉框,可能50条下拉记录也会显得过多。
有时,如果您确实需要在页面执行的过程中改变Dataset中的代码数据并且希望这些新的数据能够反应到mapValue的翻译结果中,那么也可以手工调用ListDropDown或DatasetDropDown的buildIndex()方法来更新索引。
实测数据:
将DatasetDropDown绑定到一个带有100条记录的Dataset上,启用其mapValue属性。并对建立索引和翻译这两个过程进行分别测试。测试机的CPU为INTER Pentium(R) 1.73G。
- 建立索引(即调用DatasetDropDown的buildIndex()方法)的耗时为0.203秒。此结果的时间是包含Dataset解析XML的时间的。如果忽略解析XML的时间的话,即在模拟第一次建立完索引之后重新再建立索引的动作,其耗时仅为0.040秒。
- 进行10000次随机的代码翻译(即调用DatasetDropDown的getLabel(code)方法)的耗时为0.313秒。
由此可见,mapValue功能的主要消耗是在Dataset解析XML和建立索引上,其后的代码翻译的效率还是很高的。也就是说代码翻译功能本身本省并不惧怕更大的数据量,但是代码数据量过大的话会导致页面初始化和网络传输的时间延长。
通过copyRecord()复制记录
Dataset的copyRecord(record)方法的作用是将给定的记录中的数据复制到Dataset的当前记录当中。copyRecord也可以复制异构的记录,如果给定的记录与本Dataset的结构并不相同,那么copyRecord只会复制其中名称匹配的那一部分字段值。
copyRecord是一个高度优化的方法,其效率高于一般情况下手工编写的复制代码。尤其是在进行连续的大批量复制时,其性能优势会更加明显。
Dorado的SampleCenter当中有一个很好的演示其使用方法的例子:
http://61.151.239.187/dorado5/performance/test-performance3.jsp
利用insertRecords()批量添加数据
有时我们的页面上会需要批量添加数据的功能,最常见的就是下面这种场景。在主页面能够点击一个诸如"批量添加员工"这样的按钮,然后系统会弹出一个"选择员工"的子窗体。用户可以在这个窗体中选择一大批员工,然后系统跟他的选择自动为主页面上的数据表格添加相应的记录。
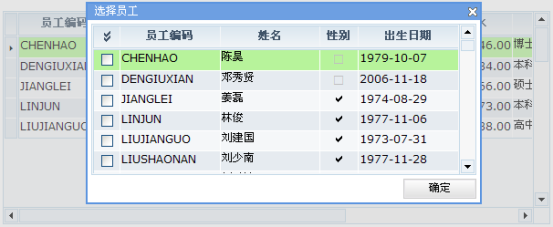
您一定已经知道,调用Dataset的insertRecord()方法可以新增一条记录。同时,Dataset还有一个insertRecords(records)方法可以用来批量的多行的记录,提供这个方法的目的就是优化批量添加记录过程的效率。
insertRecords(records)一般都会跟3.4.10中介绍的copyRecord(record)一起使用。在上面的场景中我们就需要同时用到这两个方法。批量添加员工的实现代码大致如下:
var records = new Array(); |
提高查找记录的效率
Dataset提供一个find()方法用于在Dataset中查找一条记录,其具体用法大致如下:
// 查找并返回一个性别为男并且薪水为5000的员工 |
find()方法非常易于使用,但是该方法的效率并不高,因为它是使用遍历的方式来查找匹配的记录。如果只是单次的执行记录查找,该方法可能是唯一的选择。不过,如果要批量的执行查找操作,它的性能劣势将会暴露出来。
考虑3.4.11中的场景,如果在执行批量员工添加时,用户要求剔除掉那些在主页面上已经存在员工,即要求主页面中的员工是不可重复添加的。那么,我们必须在添加记录的过程中不断的进行记录查找。
要提高查找操作的效率,我们需要为Dataset建立索引,3.4.9中mapValue做的那样。可惜,Dorado的Dataset并没有提供建立索引的方法。这并不是什么问题,因为利用JavaScript Object本身的特性来实现索引非常简单。
下面的代码是利用JavaScript索引改进3.4.11中的代码后得到的。
// 创建一个JavaScript对象 |
注意上面代码中的keyMap[record.getString("employee_id")],此处特意使用了record的getString()方法而不是getValue()方法。这是因为此处的键值不能使用String之外的其他数据类型,这是由JavaScript的语言特性所决定的。使用getString()是为了确保存入keyMap的键值是String类型的数据。与键值匹配的饿数据的类型是不受限制的,可以使用任何类型的对象。在上例中,我们存入的总是逻辑值true。
要完全读懂上面的代码需要具备一些有关JavaScript Object的知识,您可以参考相关的JavaScript资料,此处不做过多的介绍。
使用异步操作
异步的远程操作是AJAX的精髓所在,它可以确保客户端在与服务器交互的过程中不影响用户的当前操作,而同步模式的远程操作却一定会造成用户进入等待状态。异步操作并不是一种针对运算的优化技巧,而是一种提高用户操作体验的技巧。使用异步操作并不会减轻客户端、服务器和网络的负载。
Dorado中的Dataset、QueryCommand、UpdateCommand、RPCCommand都支持以异步方式来执行远程方法。不过,在默认情况下我们使用的都是同步模式。一来是因为异步方式对于开发人员的要求较高,其使用方法不像同步方法般容易掌握;二来是因为不是所有的远程操作都有必要使用异步方式。对于那些用户必须等待其执行结果来决定下一步动作的操作,使用异步方式或同步方式,就操作体验而言是没有什么差别的。
所以,我们可以在下列情况下考虑使用异步操作。
- 用于实现辅助功能的远程操作,即用户不需要根据其执行结果来决定下一步动作的操作。例如从后台提取一些参考信息并显示到页面中。
- 一些依赖远程操作完成的数据校验。
- 预判用户的下一步操作,在客户端的后台执行一些远程操作并将其执行结果缓存起来等待使用。3.4.9节中介绍过的下拉框的自动热身功能就可算作是一个此类操作。
- 自动到服务端查询状态更新的操作。例如一个可以动态更新股票价格的页面;或者在类似即使通讯的界面中定时的向服务器询问是否有新的消息。
这里有一个隐喻,我们可以把同步模式的页面看作单线程程序,而把异步模式的页面看作是多线程程序。
实例分析:
- 场景一
现要设计一个商品成交记录查询界面,可根据用户输入的时间段等参数进行查询。查询结果按照每页50条记录分页显示,同时在页面的最下方显示出所有符合查询条件的成交记录的总成交金额、总数量等汇总信息。在实做时,此处定义了两个Dataset,分别对应两段SQL命令,一个用于获得分页查询结果,另一个用于获得总成交金额等汇总信息。每次查询将执行这两个Dataset的flushData()方法。由于数据量十分庞大,SQL的执行速度有点偏慢。其中用于获得分页查询结果的SQL每次执行约耗时1.5秒,而用于获得汇总信息的的SQL每次执行约耗时2.5秒。用户可接受的查询等待时间为3秒。因此,如果采用通常的方式进行开发将无法满足用户的需求。
如果我们采用传统的同步方式依次执行此处的两个SQL,那么单SQL的执行时间就将花去1.5+2.5=4秒,外加网络传输等因素,查询的响应时间可能将是4.5-5秒。这已经超出了用户要求的范围。为了缩短响应时间,我们可以考虑将此处的其中用于获得汇总信息的SQL的执行过程改为异步模式。
具体做法是将代表汇总信息的Dataset的async属性设为true,这样该Dataset将以异步模式执行flushData()操作。每当用户点击查询按钮时,设置好两个Dataset的查询参数之后,首先调用汇总信息的Dataset的flushData()方法,接着调用另一个Dataset的flushData()方法。由于第一个flushData()是一个异步操作,所以系统不会等待其执行完成就会紧接着启动第二个flushData()。当第二个flushData()执行完成之后,查询到的成交记录立刻就会在显示出来。获取成交记录的SQL大概需耗时1.5秒,到此时为止应该距离用户点击查询按钮只有2秒所有的时间。尽管此时汇总信息可能还没有显示出来,但是对于用户而言,等待已经结束了。0.5秒以后,在他正准备读一读这些成交记录的时候,取得汇总信息的SQL已在服务端执行完成。至多再过0.5秒,汇总信息也将在页面上显示出来。
可见利用异步的方式,我们可以将用户的等待时间缩短到2秒,即使是查询信息完全显示出来的总耗时,也将从原先的至少4.5秒缩短到3秒。
在这个例子中,我们也可以考虑将两个Dataset都设为异步模式。这样,不管哪个先执行完成都先把结果显示到页面上。
- 场景二
我们设计了一个人员信息的录入界面,用户每天可能要在此页面中录入几百个人员信息。为了使用户能够流畅的录入数据,此处使用一个数据表格作为录入控件。人员信息中包含一个人员编号的字段,现在希望在提交之前系统能够对录入的人员编号做一个校验,确认该编号确实存在于系统数据库中。该校验操作被封装为一个RPCCommand的调用并在Dataset的afterChange事件中被触发。
经实测每次校验过程大约会耗时0.5秒。这个数据看起来并不大,可是当用户在进行密集的输入操作时,他仍能感觉到每次输完一个人员编号之后系统都会有一个明显的停顿。特别是当他每天要面对几百次这样的停顿时,心情就会因此而变的糟糕。
改进的方法是将RPCCommand的async属性设为true,并且在afterChange事件中以下面的方式来调用。
function afterChange(dataset, recored, field, oldValue) { |
利用UpdateCommand的数据感知特性减少flushData()
常常有开发人员喜欢在UpdateCommand的onSuccess事件中大量调用Dataset的flushData()方法。这些调用基本上都是为了解决同一种问题 —— 使客户端获得那些在服务端提交处理过程中产生的信息。例如:在新合同保存的过程中有服务端的逻辑分配的合同号;或者由服务端填入的当前日期等信息。为了使用户能够在页面不刷新的情况下能够看到这些信息、或者继续操作该页面,开发人员往往喜欢调用flushData()方法。这些flushData()的耗时有时会大大的超过执行提交动作本身的耗时。例如:当客户端一次提交了7个Dataset时,常常就会紧跟着7个flushData()。将这7个Dataset都改为异步模式或许可算作是一种优化方法,但在Dorado中我们还能找到更好的解决方法 —— 利用UpdateCommand的数据感知特性。
UpdateCommand的数据感知特性是指Dorado能够感知那些被提交的记录在服务端发生的变化,并且自动将这些变化传回客户端的功能。在Dorado的SampleCenter中有一个很好的用于演示此功能的例子,
http://61.151.239.187/dorado5/new-feature/new-dataset.jsp注意其中的"动态数据更新"的演示,在执行提交的过程中Dataset可以直接获得那些在服务端产生的新数据。
UpdateCommand的数据感知特性在基于SQL和基于POJO这两种开发模式下的使用方式略有不同。
- 基于SQL的开发模式下的数据感知
在这种开发模式下,数据提交的处理逻辑一般是写在ViewModel的实现类中的,此时Dorado监听对程序对Dataset中记录的修改动作。例如在下面的代码中,Dorado将会感知到datasetEmployee.setFloat("salary", salary)命令对数据的修改并把它传回给客户端。
public void raiseSalary(ParameterSet parameters, ParameterSet outParameters) |
除了修改,删除操作也在被监听的范围内。不过,在服务端所做的新增操作不会引起该机制的注意。在下面的代码中,删除操作将被感知被反应到客户端的Dataset中。
public void deleteSelection(ParameterSet parameters, |
使用SQL开发模式时还有一个需要注意的问题 —— 主键的产生方式。很多数据库都支持自动生成主键,像MS SQLServer、MySQL等。利用JDBC规范中的getGeneratedKeys()方法,Dorado可以利用此功能自动获得数据新产生的主键值(此功能在部分数据库的JDBC驱动中没有被实现)。具体做法是将SqlDataset或AutoSqlDataset的retrieveAfterUpdate属性设为true,该属性在默认情况下是关闭的。
- 基于POJO的开发模式下的数据感知
在这种开发模式中,开发人员操作的并不是Dorado的Dataset或Record,而是POJO类新的数据。并不是问题,Dorado同样可以监视对这些对象的修改动作。以Marmot为例,下面的代码中的employee.setSalary(newSalary)操作将被Dorado感知到。
public Object raiseSalary(Map dataSetMap, Object parameter) |
{kind=link}