把业务逻辑代码留在服务端
经验不足的开发人员在使用Dorado的客户端编程的过程很容易在不知不觉误入歧途。其中很常见的一种错误就是将原本应该在服务端执行的逻辑放到了客户端。
Dorado(或者说AJAX)为Web应用带来的一个很重要的变化就是把一部分的原本只能在服务端执行的逻辑推到了客户端,通过这种方式可以在很大程度上减少客户端与服务器的通讯次数并改善用户的操作体验。例如一些简单对输入数据的校验功能,在传统的开发模式中,只能等到最终点击了提交按钮,系统才能执行校验动作。而在Dorado的方式中,系统可以直接利用前台的JavaScript,在用户输入的过程中告知其校验结果。不过,如果在开发过程中过度的利用了这一特点,结果往往就会适得其反。
究竟哪些逻辑应该留在服务端?我们认为有下面这几种情况:
- 重量级运算。即在JavaScript中进行可能会花去较多时间的操作。
- 频繁通讯。即在运算过程中需要多次往返于客户端和服务器的操作。
- 敏感操作。即对安全性要求较高的操作。
为了便于理解上面的几种情况,我们来分析几个失败的案例。
- 失败的案例一,违反"重量级运算"原则。
在一套进销存系统中有这样一个功能要求,利用已经签订的某笔产品销售合同自动生成产品采购合同。这样,就可以在部分情况下免去用户大量录入产品采购合同的工作量。销售合同只要设计到两张数据库表,分别是合同的主信息(包括客户、日期、条款等)和合同的明细信息(主要是指合同中的产品信息、数量、单价等)。采购合同的整体结构与其类似。同时在复制的过程当中还应该注意一些细节,向销售单价之类的信息是不需要一起复制到采购合同中的。
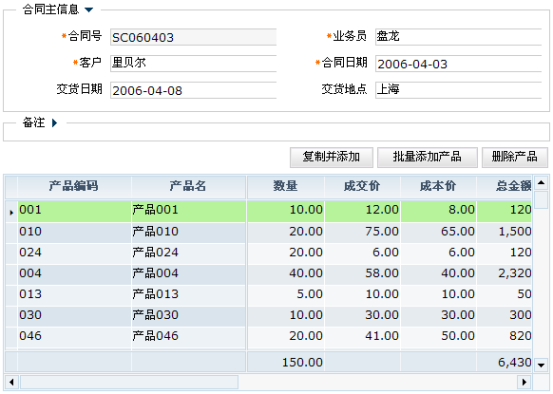
错误的做法是在某一个ViewModel中定义四个Dataset,分别对应销售合同主信息、销售合同明细信息、采购合同主信息和采购合同明细信息。然后利用Dorado提供的Dataset.copyRecord等方法,在客户端执行Dataset到Dataset的数据复制。
不可否认,在Dorado中这样来实现一点都不麻烦,但是他的效率却完全得不到保障。因为一个合同的内容有可能是非常庞大的,图中所显示的只是一个精简的例子。有时一个合同的明细项就有可能多达上千条!这样的数据量在JavaScript中进行复制,其效率是不难想的。
我们认为正确的做法应该是,客户端不要为这个功能提供任何特别的支持,而是仅仅提供一个"合同自动生成"这样的按钮。当用户点击按钮后,只向服务端发送要执行的操作和销售合同号,然后依靠服务端的代码进行采购合同的自动生成。当处理完成之后,直接引导用户打开新产生的采购合同进行进一步的维护。
- 失败的案例二,违反"重量级运算"原则。
假设我们正在开发一个为操作员分配操作权限的页面。要求在页面打开时列出所有所有可被用于分配的操作权限项,并且在每一个操作权限项后都带有一个复选框。当我们要将某一个操作权限赋予操作员时,只需要勾选相应的复选框就可以了。这个页面的难点在于,当某个操作员已经拥有了一部分权限时,那么页面打开的时候相应的复选框就应该默认处于被勾选的状态。
TODO: 加一张截图
错误的做法是,在ViewModel中建立两个Dataset。其中一个Dataset包含所有可被分配的操作权限项,其中还预留了一个字段保存勾选状态,不过一开始是没有任何数据的;另一个Dataset包含该操作员目前已获得的操作权限。然后在ViewModel的onLoad事件中,对两个Dataset进行遍历(或者诸如此类的操作,目的是在Dataset查找记录),将第二个Dataset中的信息反映到第一个Dataset中的那个预留字段中。
这种的做法的缺点同样是客户端的JavaScript运算量过大。当权限项的数据量较大时,页面打开时的初始化耗时可能会急剧增加。还有一种交叉表的页面需求也常常会导致这样的错误出现。
正确的做法应该是在服务端实现组装好我们所需要的数据结构。如果直接利用SQL产生当然最为简单。即使无法直接利用SQL,而是使用HashMap之类的编程技巧,其效率也远远优于前面的做法,尽管他们的算法看起来是一样的。
- 失败的案例三,违反"频繁通讯"原则。
想象在采购合同维护的页面当中就一个"批量添加产品"按钮。用户可以在一个弹出式的窗体中批量的选择一组产品追加到合同的明细列表当中,同时用户要求在向采购合同中追加记录时,自动的为每一个产品填好其上一次采购时的采购单价。由于下图中的"选择产品"页面是一种系统中的通用页面,它只能给主页面最基本的产品编码、名称这样的信息。因此,我们只能通过Dorado的Dataset.flushData或RPCCommand从服务端提取每个产品的最后成交采购价。
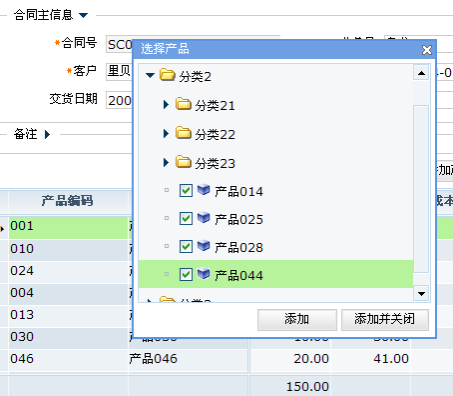
最容易实现的、也是不正确的做法是,在客户端添加产品的循环体中添加一段代码,在向明细列表中添加每一个产品时,都利用Dataset.flushData或RPCCommand从服务端提取该产品的采购价格。试想如果用户一次性在子窗体中选择了20个产品,那么在批量添加产品的过程中就会产生20次的远程过程调用。对用户而言,这一定会是一个相当受煎熬的等待过程。
我们认为远程通讯(远程过程调用)是一个很昂贵的过程,因此,一定要设法减少远程通讯的次数。在不改变任何操作模式的前提下,正确的做法应该是这样的。在添加产品的过程中利用Array等搜集所有的产品ID,但不调用任何服务端逻辑。直到添加产品的循环结束之后,利用一个RPCCommand调用,一次性的将所有Array中的产品ID传递给服务端,然后利用服务端的逻辑提取出这些产品的采购价格,并一次性返回给客户端。最后,利用客户端的代码把这些价格依次设置到每一个产品当中。如此,在整个产品添加的过程中只会产生一次远程过程调用,并且用户的操作体验(除速度之外)不会有任何改变。
避免LookupField的过度使用
Dorado中的Lookup功能对于"将代码翻译为名称"而言是非常方便易用的,Lookup的执行效率也是不错的。不过,如果在开发过程毫无节制的应用则有可能会带来性能障碍。要了解性能障碍的原因,我们需要简单了解一下Lookup的实现机制。
Lookup有时可以完成跟SQL的Join类似的功能,但是Lookup是在应用服务器的内存当中进行的,Lookup依赖与一个独立的Dataset(代码表Dataset)。试想在每一笔合同记录中都有一个合同状态字段,其中是以数字表示的状态码,每一种状态码所对应的状态描述保存在一个独立的数据库表中。现在要利用Lookup功能为合同记录添加一个状态描述字段。那么在系统至少应该存在两个Dataset,一个是合同信息的Dataset,另一个是状态信息的Dataset(即代码表Dataset)。Lookup机制将在内存中为状态信息的Dataset建立索引,内存索引的机制类似与HashMap。而后再对合同信息的Dataset进行遍历,依次利用索引将状态描述赋值到合同信息的Dataset中。这里包含了两个要点:
- Lookup需要一个独立的代码表Dataset为其服务,它可能会带来一次数据提取的操作。
- 代码表Dataset中的数据需要首先被装载到内存当中。
因此,在使用Lookup的过程中应该注意下面的一些细节。
- 代码表Dataset不能进行分页操作。因为分页很可能会导致部分数据无法被Lookup检索到(它们根本没有被取到内存中)。当一个Dataset的作用是所谓被Lookup的代码表Dataset时,我们需要手工的将该Dataset的pageSize设置为0。
由此如果分页不被支持,那么数据量庞大的代码表将是不适用于Lookup的。因为将这么多的数据装载到内存中并建立进行处理将是一笔不可忽视的开销。我们认为一般而言应避免将记录数大于1000的表用作Lookup代码表。同时,应该尽可能缩减Lookup代码表的字段个数,只保留必须的字段。
- 对于代码表Dataset而言,scope属性是相当重要的。因为如果代码表中的数据是相对稳定的,即一般不会被改变的。那么,我们完全可以考虑在它装载数据并建立好内存索引之后,将它暂时缓存起来。这样Dorado可以不必在每次要用到它时都重新执行装载和索引这些过程。这虽会占用一些内存,但对于提高响应速度是有帮助的。
将scope设置为application,可以达到将Dataset暂时缓存的目的。还有一个timeout属性可以跟scope配合起来使用,timeout表示当一个被缓存的Dataset在内存中空闲多久以后才可以被自动回收。在home/setting.xml中module.dataset.cache.defaultTimeout这一项表示系统默认的timeout,目前的默认值为12000,即两分钟。如果手工定义了Dataset的timeout属性,那么最终生效的将是手工定义的数值。
当一套系统中存在大量的scope为application的Dataset时,可能会占用较多的内存。因此在系统开发的过程中须保持对内存使用量的关注。这里所说的内存占用量与缓存Dataset的个数、Dataset中的数据量、timeout的长短、系统访问频率、访问模式等都是相关的。访问模式需要特别解释一下,如果在一个系统中存在大量的scope为application的Dataset,可是在日常的运行过程中只有一小部分是经常被用到的,那么只要timeout配置的得当,就不会有大量的Dataset常驻在内存当中。
一般而言,我们不推荐将scope设置为session。这会造成Dorado为每个Session建立一个独立的Dataset缓存,对内存的消耗将更加严重。同时,我们也很少有需要这样来配置。
实测数据:
以下是一些在普通PC机上得到的实测数据,实测环境的CPU为INTER Pentium(R) 1.73G。其中主Dataset中包含1000条记录,代码表Dataset中同样包含1000条记录。如此在每次页面刷新的过程中,将执行1000次的Lookup运算。
将代码表Dataset的scope设置为application,取第2次到第6次的测试结果如下:
1000次Lookup的耗时(秒) |
0.031 |
0.016 |
0.015 |
0.015 |
0.015 |
不设置Dataset的scope属性,即每次Dorado都会重新构建代码表Dataset。取第2次到第6次的测试结果如下(注意,下面列出的数据是扣除执行SQL所消耗的时间的):
1000次Lookup的耗时(秒) |
0.047 |
0.047 |
0.031 |
0.043 |
0.047 |
从这里的测试结果可见,Lookup机制的执行效率是相当高效的。
用好ViewModel的实现类
在Dorado中我们经常需要定义一个ViewModel的实现类,以此来封装一些自己的界面逻辑。ViewModel中常用的方法并不多,不过它们常常不想它们看起来那么容易使用。有一些细节必须时刻保持注意,不然你很可能会写出一些有问题的ViewModel实现类。
ViewModel不会在服务端进行缓存。我们也可以把ViewModel看做是服务端跟客户端进行信息交换的接口。当用户执行页面请求、局部数据刷新、远程方法调用等操作时服务端都会创建相应的ViewModel 实例。我们可以通过其state属性来判断当前ViewModel在何种情况下被创建。state有下列几种取值:
- ViewModel.STATE_VIEW - 打开视图状态。即用户请求一个新的视图时的状态。在此状态下ViewModel在创建时会自动创建所有已声明的Dataset,并自动根据每个Dataset的配置来装载数据。所有的控件(Control)将以懒装载的方式被创建。
- ViewModel.STATE_SERVICE - 服务状态。当一个已打开的视图在执行局部数据刷新、远程方法调用等操作时的状态。在此状态下ViewModel中所有的Dataset和控件(Control)将以懒装载的方式被创建。
- ViewModel.STATE_DESIGN - 设计时状态。该状态只有在为dorado studio提供服务时有效。
通常,我们会在ViewModel的实现类中使用到下列的一些方法。这些方法都来自与父类,在大多数情况下,使用时都需要利用super保留字调用父类中的逻辑。
- void init(int state) - ViewModel的初始化方法。参数为ViewModel当前的状态。
- void initDatasets() - ViewModel的初始化其中的各个Dataset的方法。如前面关于ViewModel状态的文字所述,究竟有那些Dataset会在该方法中被初始化是取决于ViewModel的当前状态的。
- void initControls() - ViewModel的初始化其中所有的不可视控件的方法。不可视控件包括下拉框、菜单、命令。其他的可视控件默认是不会在此处初始化的,它们甚至还没有被创建。可视控件默认都是"懒创建"的,只有当将来JSP的Taglib真正引用到它或者用户利用ViewModel的getControl(id)方法获取它时才会被创建起来。
- void initControl(Control control) - 此方法会在initControls()的执行过程中以及JSP的执行过程中,针对每一个创建出来的控件被激发。
- void doLoadData() - 当ViewModel开始为其中的Dataset装载数据时调用的方法。只有在initDatasets()中已被初始化的Dataset才会在此处装载数据,因此究竟有那些Dataset会被处理是取决于ViewModel的当前状态的。
- void doLoadData(ViewDataset dataset) - 此方法会在doLoadData()的执行过程中针对每一个要处理的Dataset被激发。如果doLoadData()中需处理3个Dataset,那么doLoadData(ViewDataset dataset)也将被调用3次。
- void doUpdateData(ParameterSet parameters, ParameterSet outParameters) - 默认的数据提交的处理方法。
以上方法不是在所有情况都会被执行的。
- 在页面打开时的处理过程是这样的。此时ViewModel的state为STATE_VIEW。
- void init(int state)
- void initDatasets() 初始化ViewModel中所有的Dataset。
- void doLoadData()
- void doLoadData(ViewDataset dataset)
- void initControls()
- void initControl(Control control)
- 执行Dataset动态数据刷新时的过程是这样。此时ViewModel的state为STATE_SERVICE。
- void init(int state)
- void initDatasets() 仅初始化当前执行数据加载动作的这一个Dataset。
- void doLoadData()
- void doLoadData(ViewDataset dataset)
- 执行数据提交时的过程是这样的。此时ViewModel的state为STATE_SERVICE。
- void init(int state)
- void initDatasets() 仅初始化被提交上来的Dataset。
- void doUpdateData(ParameterSet parameters, ParameterSet outParameters)
由此,在使用ViewModel实现类时应注意下面的一些事项。
- 最好不要将自定义的初始化Dataset或Control的代码写在init()中,因为init()会在ViewModel的每一种状态下被执行。例如你在init()中写了一段自动为DataTable创建表格列的代码,那么当界面上某个Dataset执行flushData()时,这段代码同样会被执行,这毫无意义的。正确的做法是写在initControls()或者initControl()中。由Dorado来帮你判断这段代码应在什么时候执行。
事实上,在实际应用中init()应该是一个很少被用到的方法。有时我们可能会在这里做一些权限的校验,判断当前登录用户是否有权访问这个ViewModel。再比如可以在这里指定ViewModel的role属性。
- 同样是这面提到的这端代码,写在initControl()中往往优于写在initControls()中。因为在initControls()中你必须通过getControl()方法才能得到你所需要的DataTable对象,而getControl()会强制Dorado创建这个DataTable对象,这会打破该对象的"懒创建"机制。对于一个只在ViewModel的XML中定义过但并没有在JSP中引用的对象,在默认情况下Dorado是根本不会创建它的,而getControl()会强制Dorado去创建它。
- 对于Dataset同样适用上面的规则。手工处理Dataset的数据加载过程时,相关的代码写在doLoadData(ViewDataset dataset)要优于doLoadData()中。在initDatasets()或doLoadData()必须利用getDataset()方法来获取某个Dataset,这会导致一些本不需要创建的Dataset被强制的创建。例如:在执行Dataset的flushData()的过程中,ViewModel中应该只有一个Dataset被创建。多创建几个Dataset有时并不是什么大的系统开销,但是多余的Dataset会引起多余的数据装载过程(如执行SQL),这是相当昂贵的操作。
其实对于针对某个Dataset的特别操作,像利用Java代码动态的为Dataset创建Field或者设定其他参数等。我们更加推荐把代码写在Dataset的Listener中,而不是前面提到的doLoadData(ViewDataset dataset)中。因为在doLoadData(ViewDataset dataset)必须判断ID来确定当前传入的是否我们所关心的那个Dataset,这有时会让代码显得有些混乱。
正确的使用EL表达式
EL表达式有点类似于脚本的,它是解释执行的。不过我们不必太过担心EL表达式的性能问题,它仍是十分高效的,尽管它的效率无法跟Java代码相比。几乎没有什么出了性能问题的系统最终能把原因归结到EL表达式上。所以,既然它是很方便使用的,那就没有必要刻意的去回避它。
出于负责任的态度,我们仍应该在开发时注意一些细节。考虑下面的这段来自与ViewModel事件的JavaScript代码:
${Script.getDataset("datasetEmployee")}.insertRecord(); |
这是一段正确的,但是很糟糕的代码。尽管它的糟糕之处如此明显,我却仍然经常在一些程序员的作品中看到它(这是CTRL+C、CTRL+V带来的诸多恶果之一)。同一段EL表达式被无端的执行了5次!如果你是一个稍有责任心的程序员,就应该把它改成下面这样:
var datasetEmployee =${Script.getDataset("datasetEmployee")}; |