大部分应用的性能调优都应该从数据库方面的开始。相对而言,数据库方面的性能问题是比较容易跟踪和定位的。而且它对性能的影响也是非常明显的,往往会带来一个数量级以上的差异。
不过,本文不会全面的介绍数据库方面的优化技巧,下面涉及到的都是与Dorado密切相关的一些技巧和注意事项。
选择高效的JOIN方式
这主要是指AutoSqlDataset中的JoinTable。JoinTable中的JoinMode属性可以用于指定关联表的引用方式。
JoinMode目前有两种取值:left_outer_join和select_expression。从一段具体的SQL来看看他们之间的差异。
- left_outer_join模式下生成的SQL命令:
SELECT
contract.contract_no,
contract.owner,
employee.employee_name AS owner_name,
contract.customer,
contract.sign_date,
contract.delivery_date,
contract.delivery_place,
contract.terms,
contract.cmnt
FROM
contract
LEFT OUTER JOIN employee employee
ON (contract.owner = employee.employee_id) - select_expression模式下生成的SQL命令:
其中,left_outer_join方式的SQL命令比较通用,可以在几乎所有主流的数据库上正确执行。而select_expression方式的SQL命令则无法在部分数据库中执行(如MySQL3)。
SELECT
contract.contract_no,
contract.owner,
(SELECT employee_name FROM employee
WHERE employee_id = contract.owner) AS owner_name,
contract.customer,
contract.sign_date,
contract.delivery_date,
contract.delivery_place,
contract.terms,
contract.cmnt
FROM
contract
对于这两种的方式在性能方面的孰优孰劣,需要根据实际情况甚至只有亲自试过之后才能断言。不过,一般而言,在数据表中的数量较大而选取的数据量不是很大的情况下,select_expression的效率可能高一些。
例如:合同表中总共有十万级的数据量,而我们现在只需要从合同表中根据合同号选取一条记录。在这种情况下,我们基本上可以认为select_expression会快过left_outer_join。
select_expression在部分情况下是不适用的,例如当关联表中的字段会在WHERE、GROUP BY中被使用到时。不过,在AutoSqlDataset中开发人员倒并不需要特别关注这种情况,因为当AutoSqlDataset察觉到这种不恰当的用法时,会自动退回到left_outer_join模式。配置正确的数据库方言
如同Hibernate,在Dorado中也提供了数据库方言机制。每一种数据库方言中都封装了有关该种或该版本数据库所特有的命令或优化方式。这其中最重要的就是关于查询分页优化的特别技巧。如下图。

例如在MySQL中,我们可以通过这样的SQL命令在处理分页查询。利用这种技巧,可以直接取出结果集的第11到20条记录。而要实现同样的功能到了ORACLE当中又变成了这样。SELECT * FROM contract
LIMIT 11, 20有时,选择了不恰当的数据库方言会导致程序执行报错。不过,在另外一些情况下系统可能仍可以无误的运转,但那些针对具体数据库提供的优化技巧将肯定无法发挥作用。这一点对于那些数据量较大的应用而言可能是致命的。SELECT * FROM ( SELECT row_.*, rownum rownum_ FROM (
SELECT * FROM contract
) row_ ) WHERE rownum_ <= 20 AND rownum_ > 11使用分页查询
在Web应用中使用分页来展示较大行数的内容早已成为了一种标准的做法。但是对于那些已经用惯了CS应用的用户,有可能仍然希望不要对数据进行分页处理。这种要求有时显得并不合理,因为对于上千条记录的结果集而言,这样的浏览方式事实上是不利于改善操作体验的。提出这要的要求经常是出于习惯性思维。不过,不管怎样你可能不得不想尽办法来满足这种的要求,用户可不会替技术人员考虑性能问题。
部分开发人员会因此放弃对结果集进行分页,当然也有部分未使用分页的情况是因为技术人员的疏失。如此一来,当查询结果达到更高的数量级时,应用将不可避免的出现性能问题。这对服务器CPU、网络、客户端CPU都是十分严峻的挑战。
我们建议在所有的情况都为Dorado的Dataset加上分页的功能(注:在默认情况,即使我们不设定pageSize,Dataset会直接使用pageSize=100来进行分页,除非手工的把pageSize属性设为0。所以此处所说的为Dataset加上分页是指不要刻意将pageSize属性设为0)。即使面对上面提到的要求,我们也可以在分页的前提下使用Dataset的autoLoadPage属性来实现。见3.4.8。精简非必要的字段
很多开发人员在编写SQL时都喜欢不假思索的取中表中的字段。有时SQL并不是完全由手工编写的,例如通过自动生成工具生成的。不管不过是哪种,结果都一样。如果不再加以处理的话,默认情况下是取出表中所有字段的。
对于系统中部分页面而言,取出这么多的字段可能是完全没有必要的。有时界面上仅仅需要显示4、5个字段,而我们的SQL却可能取出了100个!这对于服务器而言可能算不了什么,人工是很难感觉到他们之间的性能差异的。不过,这样做却往往会导致另一个结果,Dataset将在客户端生成100个字段,而事实上页面上用到的可能只不过是4、5个。这里有一个需要了解的事实是我们在表格上看到很可能并不是Dataset当中所有的列,其他的列的数据虽没有显示,却仍需要下载和处理。JavaScript的运算速度跟服务端的Java有着天壤之别,在客户端处理100个字段和处理4、5个字段间的性能差异将被放大。同时,将100个字段中的数据全部在下载到客户端所带来的网络流量的消耗也是不可忽视的。
所以,有可能的话,最好从SQL中把实际并不需要的字段剔除掉。即使你觉得这些做太麻烦,或者因为逻辑运算的需要你必须取出所有字段。那么,您至少也应该从相关的Dorado Dataset中删除掉不需要的字段。
关于Dataset如何创建其中的字段存在下列一些规则。 - 当Dataset的autoCreateFields属性为true时,Dataset总是会在服务端的初始化过程中自动创建出所有可能的字段。autoCreateFields属性的默认值为false。例如,使用SqlDataset或AutoSqlDataset时,Dataset会自动根据查询结果集中所有的列创建字段;或者使用MarmotDataset时,Dataset会自动根据objectClazz属性指定的对象类型,通过反射机制挖掘出所有的对象属性,并创建相应字段。
- 当Dataset的autoCreateFields属性为false,但开发人员没有在Dataset中显式的定义过任何字段,此时Dataset同样会在服务端的初始化过程中自动创建出所有可能的字段。创建规则同上。
- 当Dataset的autoCreateFields属性为false,并且开发人员已经在Dataset中显式的定义过了一些字段,此时Dataset将只创建已经定义过的字段。如下图中所展示的状态。
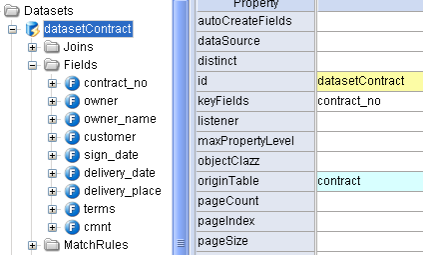
所以,当SQL取出了较多的字段而你又不希望他们全部被生成到客户端时,应该按照上面的最后一种方式来定义你的Dataset。