情景描述
本事例是按照客户向供应商购买服务包的应用场景制作的关于有限资源完全与非完全分配的模型,图1.2是我们希望达到的效果。
典型界面
为了完整的模拟这种场景,我们将演示其中最重要的两个步骤:
第一步:登记资源,如图1.1。
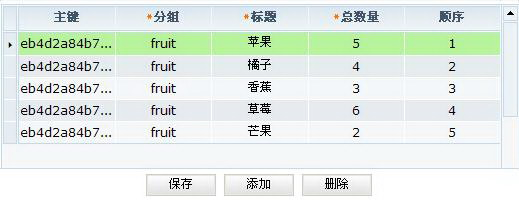
图1.1 资源登记
第二步:分配资源,如图1.2。

图1.2 分配资源
另外在资源分配时还要做一些保护工作,如图1.3。
保护:当没有资源可以分配时,需要给出提醒并阻止不正确的分配。

图1.3 资源分配中的约束
数据库准备
我们需要3张表:
第一张:Mark_Resource资源信息表,结构如下图:
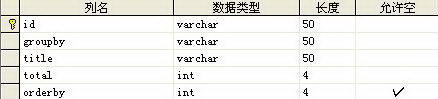
第二张:Mark_People人员信息表,结构如下图:

第三张:Mark_People_Resource资源分配表,结构如下图:

解决思路
图1.1资源登记的思路如下:
- 使用keyGenerator为资源分配主键。
- 使用DataTable组件,保证批量数据的录入。
图1.2与图1.3分配资源的思路如下:
- 定义一个CustomDataset叫做datasetResource。
- datasetResource预定义两个字段key、name分别代表资源分配接收者的主键和名字。
- 在服务器端视图模型的initDatasets方法中根据资源分组依据访问数据库,从Mark_Resource资源表中获得资源。
- 根据获得的资源为datasetResource添加字段。其中资源的主键作为字段的name,资源的名称作为字段的label;每个资源的最大数量信息被记录在dataResource的$maxSumString参数中。
- 在服务器端视图模型的doLoadData方法中为datasetResource填充记录。访问数据库,从Mark_People表中获得人员信息,向datasetResource中填充记录,可以正确填充key与name字段内容;根据资源分组依据从Mark_People_Resource获得资源的已分配的信息,正确填充动态生成字段的内容。
- 客户端使用DataTable显示信息。
- 资源字段使用CheckBox渲染,并且自定义两个属性sum和maxSum分别表示资源总量和已经分配的数量。maxSum的值通过解析datasetResource的$maxSumString参数值获得,sum通过遍历datasetResource获得。
- 利用DataTable的onFooterRefresh事件实时反应资源的分配情况。
- 利用Dataset的beforeChange事件保证资源分配的正确性。
知识点
使用自定义的数据源
在JDBC盛行的时代里很多公司自主开发了持久层解决方案,经过多个项目的考验后,通常能够满足特定领域的需求。Dorado 为这类持久层提供了方便的集成接口,步骤如下:1. 在datasource.xml声明我们自定义的数据源,配置如图1.4:
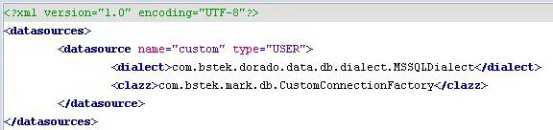
图1.4 自定义数据源的配置信息
从上图中我们可以看出如下信息:
1. 自定义数据源的类型一定是USER(即type="USER")。
2. 该数据源的名称为custom。 3. 该数据源的方言为com.bstek.dorado.data.db.dialect.MSSQLDialect,即使用SQLServer数据库。
4. 该数据源的实现类为com.bstek.mark.db.CustomConnectionFactory,当我们需要使用java.sql.Connection时,dorado 会自动的从这个类中获取。
2. 你大概对com.bstek.mark.db.CustomConnectionFactory感兴趣了,事实上它继承了com.bstek.dorado.common.ds.DataSourceConfig类,并且仅仅需要实现public Connection getConnection()方法,如下代码。
public Connection getConnection() {
String url = "jdbc:microsoft:sqlserver:" +
"//localhost:1433;DatabaseName=markdemo";
String user = "sa";
String password = "";
Connection conn = null;
try {
Class.forName("com.microsoft.jdbc." +
"sqlserver.SQLServerDriver").newInstance();
conn = DriverManager.getConnection(url, user, password);
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
} |
上面的代码硬编码了使用JDBC获取数据库的连接仅仅是为了演示该功能的代码接口而已,实际生产中这里会调用公司内部持久层来获得与数据库的连接。
3. 经过了上面的两个步骤后,我们就可以使用该数据源了,方法与使用JDBC或JNDI方式完全相同。例如在图1.5中我们使用custom数据源定义了一个AutoSqlDataset,id为datasetResource,对应的数据库表为mark_resource。

图1.5 使用自定义数据源
利用keyGenerator属性为记录自动分配主键
在图1.5中注意到在字段id中定义了一叫做keyGenerator的属性,这是在使用Dorado的主键生成功能,保证我们不需要书写JAVA代码就可以自动的为插入到数据库的记录分配主键,这样可以脱离枯燥的分配主键的循环的JAVA代码,具体步骤如下:
- 定义全局的主键生成策略,在setting.xml中配置data.keyGenerator。
<property name="data.keyGenerator" value=" com.bstek.mark.key.DemoKeyGenerator "/> |
- 上面的com.bstek.mark.key.DemoKeyGenerator类就是产生主键的工厂,需要实现com.bstek.dorado.data.KeyGenerator接口,事例代码如下:
public class DemoKeyGenerator implements KeyGenerator {
public String getKey(Dataset dataset, ReadRecord record, String value)
throws Exception {
String key = UniqueKey.getKey();
return key;
}
} |
- 在DBDataset的主键字段中配置keyGenerator属性,如图1.6。
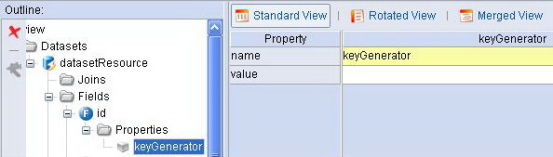
图1.6 使用keyGenerator
在上图中并没有配置keyGenerator属性的value值,事实上这里配制的value值会传递到DemoKeyGenerator的getKey方法的第三个参数中(即String value的参数),也就是说如果我们具有很多个主键生成策略,那么可以通过value的值来选择不同的策略,所以DemoKeyGenerator的职能更加像是主键分配策略的工厂。当然我们也可以通过Dataset或者ReadRecord参数来选择策略,不过这样的设计复杂了一些,最简单的就是仅仅使用一种策略。如果项目中使用的是Oracle数据库并且唯一的主键分配策略是从不同的Sequence中获得的键值,那么Dorado已经为我们提供了这样的keyGenerator,使用时setting.xml做如下配置:
<property name="data.keyGenerator" value="
com.bstek.dorado.data.db.dialect.OracleSequenceKeyGenerator"/> |
另外主键字段的keyGenerator属性的value中填写Sequence的名称,如图1.7。
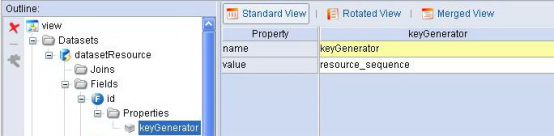
图1.7 使用OracleSequenceKeyGenerator的字段配置
注:实现图1.1的功能我们只用到了上面的两个知识点,没有书写任何JAVA代码,主体功能只需要配置信息就可以完成,所以具体实现不在这里累述,图1.2的功能需要重点描述。
服务器端动态为Dataset添加字段。
在访问图1.2即资源分配的页面时,我们需要知道对哪组资源进行分配,分组信息通过URL参数传递,所以URL中应该包含groupby=xxx的参数,本事例中使用groupby=fruit。当知道了资源分组信息后,我们就可以访问数据库得到该组下的所有资源了,每一种资源作为dataset的一个字段存在,所以字段的数量不是确定的,我们需要调用Server端Dataset与BaseField的API动态的为dataset添加字段,通常来说这个步骤是在视图模型的initDatasets()中做。图1.8是该方法的完整代码:
protected void initDatasets() throws Exception {
super.initDatasets();
if (this.getState() == ViewModel.STATE_VIEW) {
//@1. 检验groupby参数
String groupby = DoradoContext.getContext().
getParameter("groupby");
if(null == groupby |
"".equals(groupby)){
throw new Exception("请在url后添加groupby参数," +
"例如:?groupby=fruit");
}
StringBuffer maxSumParameter = new StringBuffer();
ViewBaseField field = null;
ViewDataset datasetResource = this.getDataset("datasetResource");
//@2. 获得需要分配的资源
DBStatement dbStmt = new DBStatement();
dbStmt.setDataSource("custom");
dbStmt.setSql("select * from mark_resource " +
"where groupby = :groupby order by orderby");
dbStmt.parameters().setString("groupby", groupby);
List result = dbStmt.queryForList();
dbStmt.close();
//@3. 为datasetResource添加字段
for(int i=0,size = result.size(); i<size; i++){
VariantSet vs = (VariantSet)result.get ; ;
field = (ViewBaseField) datasetResource.
addField(vs.getString("id"));
field.setDataType("int");
field.setDefaultValue(0);
field.setLabel(vs.getString("title"));
maxSumParameter.append(field.getName() + ":" +
vs.getInt("total") + ";");
}
datasetResource.parameters().setString("$maxSumString",
maxSumParameter.toString());
}
} |
图1.8 动态为Dataset添加字段
在图1.8中我们遍历通过资源分组信息得到的资源列表为datasetResource添加字段,资源的id作为了字段的id,资源的title作为了字段的label,并且字段为int 类型默认值为0。还注意到为datasetResource添加了$maxSumString的参数,其值为:"资源ID :资源数量;"格式组成的字符串,作用是在客户端为资源分配的限制提供依据。
既然字段是动态生成的那么向dataset中添加数据是不是很困难呢?通常不会很困难,因为字段是根据业务动态添加的,数据也是根据业务填充的,由于来源于相同的依据,所以并不会有很大的阻力,图1.9是向datasetResource填充正确数据的完整代码,由于在这个场景中不能一次给予datasetResource正确的记录,所以使用了一个小技巧,利用HashMap为datasetResource记录建立ID的索引。
protected void doLoadData(ViewDataset dataset) throws Exception {
super.doLoadData(dataset);
if (this.getState() == ViewModel.STATE_VIEW &&
dataset.getId().equals("datasetResource")) {
//@1. 检验groupby
String groupby = DoradoContext.getContext().
getParameter("groupby");
if(null == groupby |
"".equals(groupby)){
throw new Exception("请在url后添加groupby参数," +
"例如:?groupby=fruit");
}
//@2. 向datasetResource中添加初始化的记录,并构造resourceRecordMap
DBStatement dbStmt = new DBStatement();
dbStmt.setDataSource("custom");
dbStmt.setSql(DBStatement.SELECT, "mark_people");
List peopleList = dbStmt.queryForList();
dbStmt.close();
Map resourceRecordMap = new HashMap(peopleList.size());
for(int i=0; i<peopleList.size(); i++){
VariantSet vs = (VariantSet)peopleList.get;
Record r = dataset.insertRecord();
r.setString("key",vs.getString("id"));
r.setString("name",vs.getString("name"));
r.setState(Record.STATE_NONE);
resourceRecordMap.put(vs.getString("id"), r);
}
dataset.moveFirst();
//@3. 为datasetResource填充真正的数据
dbStmt.setSql(DBStatement.SELECT, "mark_people_resource");
dbStmt.parameters().setString("groupby", groupby);
List peopleResourceList = dbStmt.queryForList();
dbStmt.close();
for(int i=0; i<peopleResourceList.size(); i++){
VariantSet vs = (VariantSet)peopleResourceList.get;
String peopleId = vs.getString("people");
Record resource = (Record)resourceRecordMap.get(peopleId);
if(null != resource){
resource.setInt(vs.getString("resource"), 1);
resource.setState(Record.STATE_NONE);
}
}
}
} |
图1.9 给datasetResource添加正确的数据
重视EventManager的使用
到目前为止我们已经可以将存储在数据库中的资源分配信息加载到Dataset中了,服务器端的工作已经结束。对页面和组件的展现形式需要通过客户端的JavaScript控制,在介绍客户端的代码之前,现看一下该视图模型的配置信息,如图1.10。
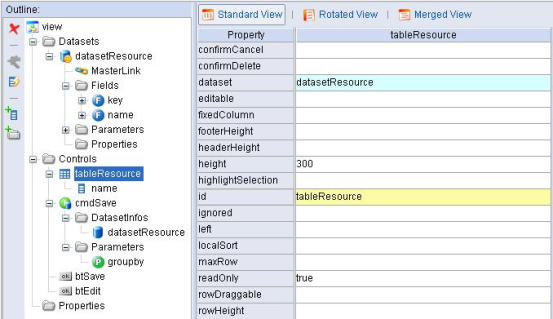
图1.10 资源分配视图模型的配置信息
由图1.9和图1.10可见,先定义了datasetResource的key与name字段,其他的字段是服务器端动态生成的。tableResource绑定了datasetResource但只定义了name列,那么其他的列是什么时候在哪里怎样添加的呢?
答:是在客户端视图模型的onDatasetsPrepared(ViewModel)事件中最终调用EventManager添加的。
图1.11是客户端onDatasetsPrepared(ViewModel)事件完整代码。
baseDataset = datasetResource;
//@1. 初始化dataset.field.maxSum
Base.initFieldMaxSum(baseDataset);
//@2. 初始化dataset.field.sum
Base.initFieldSum(baseDataset);
//@3. 给dataset添加约束
EventManager.addDoradoEvent(baseDataset,
"beforeChange",Base.updateFieldSum);
//@4. 初始化datatable.column
Base.initDatatableColumn(baseDataset,tableResource);
//@5. 初始化btEdit的onClick事件
EventManager.addDoradoEvent(btEdit, "onClick",
function(button){
Base.DataTabletoEditState(tableResource);
button.disabled = true;
btSave.disabled = false;
});
//@6. 成功保存后的动作
EventManager.addDoradoEvent(cmdSave,"onSuccess",
function(command){
Base.DataTabletoReadState(tableResource);
btSave.disabled = true;
btEdit.disabled = false;
}); |
图1.11 onDatasetsPrepared(ViewModel)事件完整代码
图1.11中的代码非常简单,只做了两件事情:
第一件:为了完成业务功能进行的初始化工作。
第二件:通过EventManager为DoradoElement添加事件。
当查看该视图模型的源文件时,你会发现我们并没有通过studio为组件和Dataset添加任何事件,事实上这些事件是使用JavaScript利用EventManager添加的。这种做法的意义远大于EventManager的功能,详细内容我们将在事例二中介绍,并且引入一种叫做VBC的面向业务的客户端编码风格。
现在需要说明客户端代码的思路了,还记得我们在服务器端为datasetResource添加一个叫做$maxSumString的参数吗?里面记录着每种资源可分配的数量。在客户端我们就会使用它了,通过调用Base.initFieldMaxSum(baseDataset);将资源可分配数量信息记录在对应字段的maxSum属性上;通过调用Base.initFieldSum(baseDataset);将资源已分配数量记录在字段的sum属性上;这两个信息通过DataTable的onFooterRefresh事件显示在footer上,对资源分配的限制是通过datasetResource的beforeChange监视的。
在图1.2中我们看到了DataTable的footer的效果,近距离观看如下图。

如果您想使用DataTable的footer,只需要将DataTable的showFooter属性设置为true。

使用footer显示什么内容可以通过onFooterRefresh事件来实现。

由于dorado提供了事件编程接口,所以可以在footer上实现动态的复杂的显示效果,在该事例的每个资源对应的Column的onFooterRefresh事件的代码是这样的:
Base.drawFooter = function(column, cell, value){
var field = baseDataset.getField(column.getField());
var footHtml ="<div style='width:100%;text-align:center'>"
+ Base.getFieldSum(baseDataset, field)
+ "/" + field.maxSum + "</div>";
cell.innerHTML = footHtml;
} |
通过Dataset的beforeChange事件维护业务约束
该事件的关键特性是:如果返回值为AbortException或DoradoException可以阻止用户对Dataset中值的修改,如果返回的是AbortException则系统会终止默认的后续操作,如果返回的是DoradoException系统会首先给出提示信息然后终止默认操作。图1.12中的Base.updateFieldSum就是datasetResource的beforeChange的事件句柄,如果用户分配资源的数量大于资源总量会返回DoradoException,效果见图1.3:
Base.updateFieldSum = function(dataset, record, field, value){
var sum = field.sum;
if(sum===undefined |
sum===null){return;}
var resultSum = 0;
switch(value){
case "0":
Base.setFieldSum(null, field, parseInt(sum)-1);
break;
case "1":
resultSum = parseInt(sum)+1;
if(resultSum > parseInt(field.maxSum)){
return new DoradoException("已经达到了最大数量,不能再分配了");
}else{
Base.setFieldSum(null, field, resultSum);
}
break;
default:
alert("other.value = " + value);
}
} |
图1.12 通过Dataset的beforeChange事件维护业务约束
代码清单
到目前为止我们已经对客户端的代码总体分析了一次,下面是详细代码,也许你还会从中看出几分珠玑,见图1.13。
var baseDataset;
var Base={};
/**
* 初始化field.sum
* @param Dataset dataset
* @param Field[] fieldArray [optional]
* 注:如果fieldArray没有值,则遍历dataset的所有field
*/
Base.initFieldSum = function(dataset,fieldArray){
if(!fieldArray){
var fieldCount = dataset.getFieldCount();
for(var i=0; i<fieldCount; i++){
Base.setFieldSum(dataset,dataset.getField);
}
}else{
var fieldCount = fieldArray.length;
for(var i=0; i<fieldCount; i++){
Base.setFieldSum(dataset,fieldArray[i]);
}
}
}
/**
* 初始化field.maxSum
* @param Dataset dataset
* @param int defaultValue
*/
Base.initFieldMaxSum = function(dataset, defaultValue){
var $maxSumString = dataset.parameters().getValue("$maxSumString");
var getFieldMaxSum = function(parameterName){
var index1 = $maxSumString.indexOf(parameterName);
if(index1<0){ return parseInt(defaultValue);}
var index2 = $maxSumString.indexOf(":", index1+parameterName.length);
var index3 = $maxSumString.indexOf(";", index2+1);
var maxSum = $maxSumString.substring(index2+1, index3);
return maxSum;
};
var field,fieldName;
for(var i=0, fieldCount=dataset.getFieldCount(); i<fieldCount; i++){
field = dataset.getField;
fieldName = field.getName();
if(fieldName=="key" |
fieldName=="name"){continue;}
field.maxSum = getFieldMaxSum(field.getName());
}
}
/**
* 给dataset添加约束
* @param Dataset dataset
* @param Record record
* @param Field field
* @param Any value
* 注:在dataset.beforeChange事件中调用的,仅仅用到了field和value参数
*/
Base.updateFieldSum = function(dataset, record, field, value){
var sum = field.sum;
if(sum===undefined |
sum===null){return;}
var resultSum = 0;
switch(value){
case "0":
Base.setFieldSum(null, field, parseInt(sum)-1);
break;
case "1":
resultSum = parseInt(sum)+1;
if(resultSum > parseInt(field.maxSum)){
return new DoradoException("已经达到了最大数量,不能再分配了");
}else{
Base.setFieldSum(null, field, resultSum);
}
break;
default:
alert("other.value = " + value);
}
}
/**
* 初始化datatable.column
* @param Dataset dataset
* @param DataTable datatable
* 注:根据dataset给datatable添加column,并设置column的相关属性和事件
*/
Base.initDatatableColumn = function(dataset,datatable){
var fieldCount = dataset.getFieldCount();
var field,column,fieldName;
for(var i=0; i<fieldCount; i++){
field = dataset.getField;
fieldName = field.getName();
switch(fieldName){
case "key":
break;
case "name":
EventManager.addDoradoEvent(datatable.getColumn("name"),"onFooterRefresh",
function(column, cell, value){
cell.innerHTML = "已分配/总量";
});
break;
default:
column = datatable.addColumn(fieldName);
column.setField(fieldName);
column.setRendererType("checkbox");
column.setAlign("center");
EventManager.addDoradoEvent(column, "onFooterRefresh", Base.drawFooter);
}
}
}
/**
* 设置field.sum
* @param Dataset dataset
* @param Field field
* @param int sum [optional]
* 注:如果sum没有值,则遍历dataset计算sum
*/
Base.setFieldSum = function(dataset, field, sum){
var fieldName = field.getName();
if(fieldName=="key" |
fieldName=="name"){return;}
//@1. 如果参数sum没有值,表示需要进行初始化
if(sum===undefined |
sum===null |
sum === ""){
var resultSum = 0;
dataset.disableControls();
var record = dataset.getFirstRecord();
while(record){
resultSum += record.getValue(fieldName);
record = record.getNextRecord();
}
dataset.enableControls();
field["sum"] = resultSum;
}else{
//@2. 如果sum有值,直接赋值便可
field["sum"] = sum;
}
}
/**
* 获得field.sum
* @param Dataset dataset
* @param Field field
* @param int defaultSum [reserve]
* 注:默认返回0
*/
Base.getFieldSum = function(dataset, field, defaultSum){
var resultSum = field["sum"];
if(resultSum===undefined |
resultSum===null |
resultSum===""){return 0;}
else{return resultSum}
}
/**
* 画datatable.column.footer
* @param Column column
* @param HTMLelement cell
* @param Any value
* 注:在datatable.column.onFooterRefresh事件中使用
*/
Base.drawFooter = function(column, cell, value){
var field = baseDataset.getField(column.getField());
var footHtml ="<div style='width:100%;text-align:center'>"
+ Base.getFieldSum(baseDataset, field)
+ "/" + field.maxSum + "</div>";
cell.innerHTML = footHtml;
}
/**
* DataTable的变为编辑状态
* @param DataTable datatable
*/
Base.DataTabletoEditState = function (datatable){
var columnCount = datatable.getColumnCount();
var column;
for(var i=0; i<columnCount; i++){
column = datatable.getColumn;
if(column.getRendererType() == "checkbox" |
column.getEditorType()=="checkbox"){
column.setRendererType("checkbox");
column.setEditorType();
}
}
datatable.rebuild();
datatable.refresh();
}
/**
* DataTable的变为只读状态
* @param DataTable datatable
*/
Base.DataTabletoReadState = function (datatable){
var columnCount = datatable.getColumnCount();
var column;
for(var i=0; i<columnCount; i++){
column = datatable.getColumn;
if(column.getRendererType() == "checkbox" |
column.getEditorType()=="checkbox"){
column.setRendererType();
column.setEditorType("checkbox");
}
}
datatable.rebuild();
datatable.refresh();
} |
图1.13 资源分配客户端完整代码
目前已经将资源分配的核心代码(服务器端以及客户端)展示完毕,在图1.14中我们将展示保存新的资源分配信息的服务器端代码,这是一个UpdateCommand执行的服务器端代码,该Command被绑定到了btSave按钮上,并且以all为datasetResource的提交范围。
public void doSave(ParameterSet parameters, ParameterSet outParameters)
throws Exception {
ViewDataset datasetResource = this.getDataset("datasetResource");
String groupby = parameters.getString("groupby");
if(null == groupby |
"".equals(groupby)){
throw new Exception("请在url后添加groupby参数,例如:" +
"?groupby=fruit");
}
//@1. 删除旧的资源分配数据
DBStatement dbStmt = new DBStatement();
dbStmt.setDataSource("custom");
dbStmt.setSql(DBStatement.DELETE, "mark_people_resource");
dbStmt.parameters().setString("groupby", groupby);
dbStmt.execute();
dbStmt.close();
//@2. 持久化新的资源分配数据
RecordIterator ri = datasetResource.recordIterator();
FieldSet fs = datasetResource.fieldSet();
int fieldCount = fs.getCount();
while(ri.hasNext()){
Record r = ri.nextRecord();
for(int i=0; i<fieldCount; i++){
String fieldName = fs.getField.getName();
if(fieldName.equals("key") |
fieldName.equals("name")){
continue;
}
String fieldValue = r.getString(fieldName);
if(Integer.parseInt(fieldValue)==1){
dbStmt.setSql(DBStatement.INSERT,
"mark_people_resource");
dbStmt.parameters().setString("people",
r.getString("key"));
dbStmt.parameters().setString("resource",
fieldName);
dbStmt.parameters().setString("groupby",
groupby);
dbStmt.execute();
}
}
}
dbStmt.close();
} |
图14 保存资源分配的服务器端代码
上面代码中需要注意的是,在UpdateCommand的服务器端代码中,我们已经不能够利用String groupby = DoradoContext.getContext().getParameter("groupby");
这样的代码获得groupby信息了,因为这是一次AJAX请求。在Dorado中通过将需要传递给服务器端的参数放到UpdateCommand的parameters中的方法实现客户端向服务器端传递参数。所以上面的代码使用String groupby = parameters.getString("groupby");来获得groupby的分组信息的。