在视图模型中,dorado提供了两个特殊的dataset对象:SqlDataset, AutoSqlDataset。这两个对象是操作数据库的直通道,可直接查询数据库,并将查询出的数据储存到dataset中,也可以根据自身保存的信息同步更新到数据库中,其中查询可以借助sql本身的强大功能,构造出足够灵活和复杂的查询结果。所以在某种程度上它们就像是数据库中的视图对象。在传统Web开发模式中,无论我们在服务器端构造出多么强大和灵活的框架系统,我们依然很难把后台的数据信息直接展现在客户端,并灵活的让客户去修改以及最终的保存,这个过程中我们往往需要大量的编码完成数据转换和信息收集才能完成客户希望实现的功能。但是如果我们在dorado系统中利用SqlDataset与AutoSqlDataset就可以很方便得将数据在最终的浏览器上展现。并且我们可以非常方便的通过鼠标键盘的操作或通过JS脚本编程对该对象内部的数据作增删改的操作,客户连续多次的修改数据后,最终向服务器发出AJAX请求一次性的将客户端修改过的数据更新到数据库中。这个过程就同我们使用一个excel表格,修改之后按保存按钮保存一样,很容易理解。开发直接而且简单。
例如如下的一个用户界面:
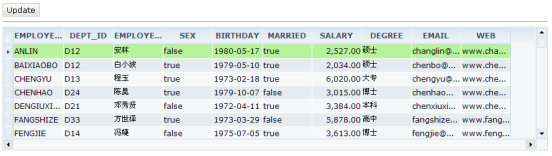
采用dorado开发技术后,这个页面的开发过程就变得很简单,完成四个操作就可以开发出来:
- 视图模型中定义一个SqlDataset或AutoSqlDataset;
- 将一个DataTable组件绑定到这个dataset上;
- 添加一个保存按钮,并设定AJAX请求相关属性;
- 利用视图模型生成JSP,并根据用户的需要调整界面布局;
这样用户就可以在浏览器中打开这个JSP,在表格中修改数据,修改好之后单击保存按钮将修改数据更新到数据库。
Dataset
主要属性
pageSize:dataset分批数据下载时每一次下载的记录数;
pageIndex:dataset分批数据下载的当前页号;
pageCount:可以分批数据下载的总页数,通常情况下都是将查询结果按照pageSize计算出来的可以分批下载数据的总页数;
possibleRecordCount:查询结果的总记录数;
objectClazz:dataset与以JavaBean作为数据源时使用的属性,用以指定对象与dataset的映射关系(该属性的详细使用方式将会在<<快速入门(二).doc>>中详细说明);
数据访问(记录指针)
dataset对自身所包含数据的存取可以通过dataset所提供的函数实现,如getString();setString()等方法,由于dataset中包含了数据库表中的多条记录,dataset提供了记录指针的概念用以标识dataset当前定位到那条记录。getString(),setString()存取函数就会直接操作指针对应的记录。在应用开发时,为了存取dataset中的数据,我们需要方便的在dataset中定位记录指针,dataset提供的相关方法有:
方法 | 说明 |
|---|---|
moveFirst() | 将记录指针移动到dataset中的第一条记录 |
moveLast() | 将记录指针移动到dataset中的最后一条记录 |
moveNext() | 将记录指针移动到dataset中的下一条记录 |
movePrev() | 将记录指针移动到dataset中的前一条记录 |
另外与记录指针有关的两个函数isFirst()与isLast(),这两个方法的返回值都是boolean类型的,它们主要用来确定指针是否位于dataset中记录的边界上。
isFirst是用来判断当前指针位置是否已到达当前页的顶端。 该值可以成立的条件如下:当Dataset的当前记录从第二条记录转到第一条记录时isFirst仍然是false, 只有当Dataset的当前记录为第一条记录时,并试图继续向前移动当前记录后isFirst才会变为true, 此时Dataset的当前记录仍然是第一条记录。
isLast()是用来判断当前指针位置是否已到达当前页的末端。 该值可以成立的条件如下:当Dataset的当前记录从倒数第二条记录转到倒数第一条记录时isLast()仍然是false, 只有当Dataset的当前记录为最后一条记录时,并试图继续向后移动当前记录后isLast()才会变为true, 此时Dataset的当前记录仍然是最后一条记录。
如果dataset为空,则isFirst()与isLast()同时为true。
方法以及使用(代码范例)
对dataset主要提供的方法如下:
clear():清空Dataset中所有的数据,注意清空并不等于数据库中数据的删除,它只是将dataset中所包含的内存中的数据信息清空;
loadData(): 根据已设定的条件读取外部数据,如SqlDataset会根据sql与datasource属性查询数据库获取数据;MaramotDataset会通过自己定义的dataProvider从Spring中的Bean中获取数据,范例:
dataset.setSql("select * from employee");
dataset.loadData();
find(java.lang.String[] fields, java.lang.Object[] values) 根据指定的条件在dataset的内部数据中查找并返回匹配的第一条记录,范例:
String[] fields = {"employee_name", "dept_id"};
String[] values = {"安林", "D1"};
Record record = dataset.find(fields, values);
find(java.lang.String field, java.lang.Object value) 根据指定的条件在dataset内部查找并返回匹配的第一条记录,范例:
Record record = dataset.find("employee_id", "ANLIN");
findAll(java.lang.String[] fields, java.lang.Object[] values) 根据指定的条件在dataset内部查找并返回所有匹配的记录;
findAll(java.lang.String field, java.lang.Object value) 据指定的条件在dataset内部查找并返回所有匹配的记录;
insertRecord() 在dataset内部添加一条记录;
deleteRecord() 删除dataset的当前记录;
deleteRecord(Record record) 删除dataset内部指定的记录,与数据库数据删除不一样,该函数并不会真正的将数据删除,而只是做一个删除标记,直到最终调用dataset的update方法的时候,才将数据更新到数据库;
dataset.deleteRecord(record);
getCurrent() 返回dataset的当前记录对象;
Record record = dataset.getCurrent();
double salary = record.getDouble("salary");
通过setCurrent()获得当前记录。范例:
Record record = dataset.find("employee_id", "ANLIN");
if (record!=null) dataset.setCurrent(record);
update() 把用户对Dataset中数据的操作更新到外部数据中;
dataset.moveFirst();
dataset.setString("employee_id", "ANLIN");
dataset.insertRecord();
dataset.setString("employee_id", "GUOLIWEI");
dataset.update();
以上代码先修改一条记录,然后又插入了一条记录,最终调用update()方法将所作的所有修改一次性的更新。
集合对象
Dataset除了提供基本的属性以及访问方法之外,还包含一些集合类型的对象,例如字段集合,数据集合与监听器集合。
fieldSet() 返回Dataset的Field集合对象,dataset中包含一到多个字段对象;
recordSet() 返回Dataset的Record集合对象;
recordIterator() 返回Dataset中所有Record的迭代器,recordSet集合对象一般都是通过该迭代器;
addDatasetListener(DatasetListener l) 新增一个DatasetEvent的事件监听器
removeDatasetListener(DatasetListener l) 删除一个DatasetEvent的事件监听器
ParameterSet parameters() 返回Dataset所有参数的集合对象;
MetaData properties() 与Dataset相关的一组属性值;
事件
除了以上dataset提供各种功能之外,dataset还提供了基于数据的JS事件处理机制。
记录的插入事件:beforeInsert();afterInsert();
数据的修改事件:beforeChange();afterChange();
记录的删除事件:beforeDelete();afterDelete();
记录的移动事件:beforeScroll();afterScroll();
当我们在客户端对dataset中的数据做各种操作时,都会自动触发以上的相应事件。Dataset中的事件大部分与数据的修改有关,dataset提供事件处理机制,不仅可以让你可以针对不同的数据修改方式进行不同的逻辑控制,也可以通过定义事件的返回值终止默认的数据修改操作,例如我们可以在一个员工查询列表页面,假设一个逻辑:删除记录时,如果被删除的员工薪水大于4000,则给出一个提示信息"不允许删除",实现的办法,就是定义这个dataset的beforeDelete事件,并在事件中加入如下的代码:
var salary = dataset.getValue("salary");
if (salary && salary>4000) return new DoradoException("抱歉!不允许删除。");
以上代码中我们通过返回一个DoradoException终止dataset当前的deleteRecord动作。DoradoException是dorado JS事件中支持的一种异常,其中的参数用以定义提示信息。一般而言这种异常都只在dataset的beforeXXX事件中返回才有效。
Dataset的beforeXXX事件中还可以支持AbortException的返回机制,如上示例代码中如果我们仅仅希望终止deleteRecord动作,但是并不想给用户提示信息,就可以通过AbortException处理,代码如下:
var salary = dataset.getValue("salary");
if (salary && salary>4000) return new AbortException();
利用这种事件处理机制我们可以实现如下的页面特效:
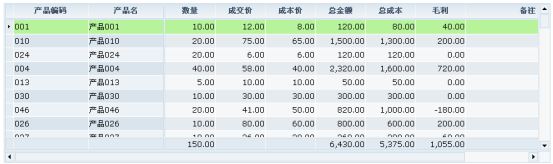
如上的表格中我们修改产品数量之后可以看到总金额、总成本、毛利都会自动计算。实现代码就是利用上述的dataset的afterChange事件机制完成:
switch (field.getName()) {
case "num":;
case "price":;
case "cost": {
// 计算单条记录中的金额,毛利..
var num = record.getValue("num");
var sum = record.getValue("price") * num;
var cost_sum = record.getValue("cost") * num;
record.setValue("sum", sum);
record.setValue("cost_sum", cost_sum);
record.setValue("profit", sum - cost_sum);
record.post();
break;
}
}
关于事件的详细说明参考<<组件使用详解.doc>>.
DBDataset
支持JDBC编程开发的Dataset的抽象基类。
Dorado针对JDBC编程提供了SqlDataset,与AutoSqlDataset,它们都继承自DBDataset,想要更好的使用它们,首先必须了解DBDataset。DBDataset具有的功能除了前面Dataset说明的之外,提供了与数据库交互方面的特性:
dialect:方言,dorado支持多种数据库的开发,并且针对不同的数据库尽可能的优化查询和提交技术,这些都是通过dialect技术实现的,在开发的时候就可以通过这个属性指定方言,不过该属性属于系统内部使用,一般情况下都不需要开发人员制定,而是在运行期由dataSource对应的方言设定决定该属性的默认值;
dataSource:JDBC编程中,dataset连接的数据源设定,该属性如果为空,运行期系统自动的到setting.xml中的common.defaultDataSource属性中查找默认的数据源,如果都没有找到,则会报错;
originTable:dataset主表的表名;
keyFields:originTable属性代表的主表的主键字段,便于唯一定位一条记录(大多数情况下为系统主键,不过却可以不一样);
isRetrieveAfterUpdate:是否需要在完成某条记录的更新后对该记录进行重新查询,也就是同步工作(视数据库类型和连接的驱动包而定,不是所有类型的数据库都支持);
dbCharSet:数据库对应的编码,默认由datasource.xml文件指定,数据库与web应用要求的编码不一致情况下,我们可以通过这个属性指定编码格式,便于dataset数据加载的时候可以自动转码;
logicCharSet:应用系统中的对应编码;
load(ResultSet rs):从java.sql.ResultSet中读取数据转换到dataset中;
load(ResultSet rs, boolean calculatePageCount):导入java.sql.ResultSet的数据的同时是否自动计算分页总数,该方法认为ResultSet是所有的查询结果集,dataset自动在该集合中根据分页设定取出部分数据,并自动计算分页总数;
loadPage(ResultSet rs):将ResultSet中的数据作为当前页自动读取到Dataset中,使用该方法时,dataset并不会再去计算分页总数,使用时需要指定dataset的pageCount属性告诉dataset总的查询结果集共有可以分多少页。
setPossibleRecordCount()/setPossibleRecordCount():设定dataset中的总记录数信息。
SqlDataset
DBDataset的子类,提供sql属性,便于开发时灵活的定制查询sql语句,dataset以此sql查询数据库。
其中sql的语法只要符合应用系统对应的数据库要求即可。另外在sql属性中,dataset还支持动态参数功能。所谓动态参数是指,开发时设定查询条件参数,运行期间动态传入参数,dataset根据动态传入的参数执行查询,并将结果返回。
如下的sql查询语句:
select * from employee where dept_id = :deptId;
我们可以在dataset运行期间动态设定dataset的参数deptId:
datasetEmployee.parameters().setString("deptId", "D11");
datasetEmployee.load();
如果我们希望在客户端实现动态参数赋值,实现AJAX效果的查询,则可以通过如下的代码实现:
datasetEmployee.parameters().setValue("deptId", "D11");
datasetEmployee.flushData();
对于SqlDataset的动态参数功能,如果你还觉得不够过瘾,则可以通过SqlDataset的setSql()方法设定sql语句:
datasetEmployee.setSql("select employee.*, dept.dept_name from employee, dept where employee.dept_id=dept.dept_id");
datasetEmployee.load();
这种用法经常在Listener中的beforeLoadData方法实现:
特别注意:
AutoSqlDataset
AutoSqlDataset也是继承自DBDataset的子类,拥有与DBDataset相同的功能。与SqlDataset相比,AutoSqlDataset中的sql属性是通过一些对象综合描述的,相关的对象有:
JoinTable: 用于描述AutoSqlDataset的关联表信息的对象
SortRule: 用于描述AutoSqlDataset的SORT BY片断的排序规则对象
MatchRule: 用于描述AutoSqlDataset的WHERE片断的匹配规则的对象.
例如两个个表关联,sql代码如下:
select employee.*, dept.dept_name from employee, dept where employee.dept_id=dept.dept_id and employee.dept_id like 'D1%' order by employee.salary descent
在AutoSqlDataset中我们可以用JoinTable描述employee与dept的关联关系:
JoinTable join1 = new JoinTable("join1");
join1.setSourceTable("employee");
join1.setSourceKeyFields("dept_id");
join1.setOriginTable("dept");
join1.setKeyFields("dept_id");
datasetEmployee.addJoinTable(join1);
用SortRule描述排序规则:
SortRule sort1 = new SortRule("employee", "salary", true);
datasetEmployee.addSortRule(sort1);
用MatchRule描述where条件:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule.LIKE, "D1%");
datasetEmployee.addBaseMatchRule(match1);
对于多个where条件,不同条件中间可能会有and或or的关系,AutoSqlDataset也提供了AndOrMatchRule对象来描述:
AndOrMatchRule match1 = new AndOrMatchRule(AndOrMatchRule.AND); datasetEmployee.addAndOrMatchRule(match1);
默认情况下,如果多个BaseMatchRule之间没有特别的添加AndOrMatchRule,则系统自动认为BaseMatchRule相互之间的关系为and关系。
同样相对于SqlDataset中拥有的动态参数功能,AutoSqlDataset中也得到支持。如上的BaseMatchRule代码可以改写为如下的代码,以支持动态参数:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule.LIKE, ":deptId");
datasetEmployee.addBaseMatchRule(match1);
为了更方便编程,AutoSqlDataset还特别提供了一种用户自定义sql的MatchRule:
SqlMatchRule match1 = new SqlMatchRule("employee.dept_id is not null");
datasetEmployee.addSqlMatchRule(match1);
通过SqlMatchRule可以使AutoSqlDataset拥有更灵活的where设定能力。
AutoSqlDataset采用这种面向对象化的方式使用SQL,同时利用datasource中的方言机制,应此在更大程度上来说AutoSqlDatset的数据库迁移更有保障。实现数据库之间的迁移更为平滑。
另外AutoSqlDataset在编程便利性上还做了更多的工作,主要有:
BaseMatchRule的逃逸功能
在使用SqlDataset的时候我们观察如下的sql语句:
select * from employee where dept_id = :deptId;
如果使用这个sql语句定义SqlDataset实现如下的界面,便于支持部门编号的查询:
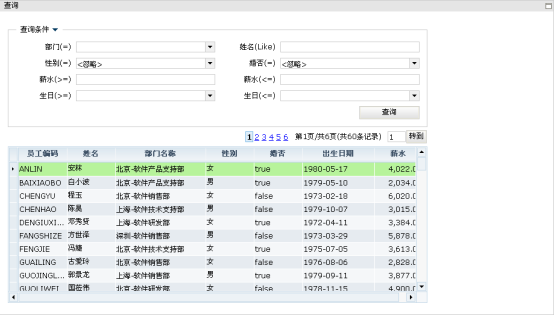
如上图,用户可以输入部门编号,按查询按钮实现查询,在很多系统的业务描述中可能会这么些:输入部门编号单击查询按钮可以查询出所输入部门的员工列表,如果部门编号为空按查询按钮时系统将所有的员工信息显示出来,并分页显示。
如果要实现上述代码,我们就必须在dataset查询时,修改服务器端的代码如下:
String deptId = dataset.parameters().getString("deptId");
String sql = "select * from employee";
if (StringHelper.isNotEmpty(deptId)){
sql += "where dept_id = '" + deptId + "'";
}
dataset.setSql(sql);
dataset.load();
这种写法当页面上有较多的查询条件时,就需要很多的if语句做各种判断,代码显得罗嗦而无效。
对于这种处理机制,BaseMatchRule提供了escape(逃逸)功能。如:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule. EQUALS, ":deptId");
match1.setEscapeEnabled(true);
datasetEmployee.addBaseMatchRule(match1);
我们通过设定BaseMatchRule的escapeEnabled属性,使它支持逃逸功能。
这段代码的效果与上面的if判断代码是等效的。
在逃逸功能中,上述代码模拟的是非空判断,在一些特殊的系统中这种逃逸有其自身的特殊性,例如有的系统中可能是这样逃逸:
if ("null".equals(deptId)){
sql += "where dept_id = '" + deptId + "'";
}
上述的逃逸逻辑为当deptId为"null"字符串时,进行逃逸。如果改为BaseMatchRule描述就可以如下设定:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule. EQUALS, ":deptId");
match1.setEscapeEnabled(true);
match1.setEscapeValue("null");
datasetEmployee.addBaseMatchRule(match1);
BaseMatchRule通过escapeValue属性指定特殊的逃逸规则,如果不做设定,效果等同于StingHelper.isNotEmpt()方法。
autoProcessParameters功能
如果你对于在AutoSqlDataset中添加那些BaseMatchRule觉得麻烦,那么你也可以直接利用autoProcessParameters功能,该属性是AutoSqlDataset的一个属性,是一个Boolean类型的变量。主要功能是将接受到的所有参数到AutoSqlDataset中查找是否有相同名称的字段,如果有则自动生成BaseMatchRule。并且这种BaseMatchRule的逃逸功能默认打开。
autoProcessParameters功能还支持匹配符和区间查询功能。
匹配符特性
由于在autoProcessParameters处理模式中,不会在设计的时候设定匹配符号,如=,>,>=,<,<=,like等,在autoProcessParameters中,直接根据参数动态生成,如:
datasetEmloyee.parameters().setString("dept_id", "=D11");
datasetEmployee.load();
系统执行时,自动的生成BaseMatchRule:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule. EQUALS, "D11");
match1.setEscapeEnabled(true);
datasetEmployee.addBaseMatchRule(match1);
而如果参数中不包含匹配符号,则系统默认用like查询非数字、日期类型的字段:
datasetEmloyee.parameters().setString("dept_id", "D1");
datasetEmployee.load();
效果等同于:
BaseMatchRule match1 = new BaseMatchRule("dept_id", BaseMatchRule.LIKE, "%D1%");
match1.setEscapeEnabled(true);
datasetEmployee.addBaseMatchRule(match1);
区间查询特性
对于数字与日期类型的数据,除了可以上述的>,<,>=,<=等类型的匹配符号之外,还支持区间查询,如:
datasetEmloyee.parameters().setString("salary", "3000,5000");
datasetEmployee.load();
效果等同于:
BaseMatchRule match1 = new BaseMatchRule("salary", BaseMatchRule. GREATEREQUAL, "3000");
match1.setEscapeEnabled(true);
datasetEmployee.addBaseMatchRule(match1);
BaseMatchRule match2 = new BaseMatchRule("dept_id", BaseMatchRule. LESSEQUAL, "5000");
match2.setEscapeEnabled(true);
datasetEmployee.addBaseMatchRule(match2);
范例查看
autoProcessParameters的典型应用可以查看doradosample中快速体验分类中的全新设计的表格,在线链接:
效果如下图:

该范例的实现就是利用了AutoSqlDataset中的autoProcessParameters特性实现的。